
BigID公司是一家以色列公司,主要提供一款平台分析类产品
公司是一家位于以色列特拉维夫和美国纽约的一家初创高科技公司,成立于2016年。在2016年的融资中该公司原计划融资210万美元,结果获得了高达1610万美元的首轮融资。在2018年,考虑到公司的解决方案可以帮助企业应对通用数据保护条例GDPR 法规的需求,BigID公司开展了1400万美元的A轮融资。截止2018年3月份,该公司拥有16名员工。
产品情况
公司从官网上看到目前就只有一款平台分析类产品。产品宣传认为其可以很好的应对GDPR、PI、PII等欧美合规要求,帮助企业更好的确保他们所拥有敏感数据的私密性,减少数据泄露,强化数据的合规保护。就满足GDPR合规性的方面,产品宣称具备以下特点:
- 数据最小化 通过重复发现和相关性确保数据最小化
- 许可管理 证明个人数据收集得到了用户的许可
- 泄露提醒 遵守 数据泄露 通告窗口
- 数据主体权利 满足客户数据可携性支持以及支持遗忘数据的权利
- 数据驻留 提供数据驻留风险的分析
产品的一些分析界面

图:产品仪表板
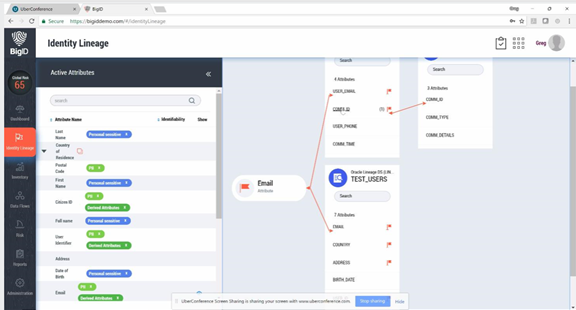
图:信息溯源

图:数据流工具
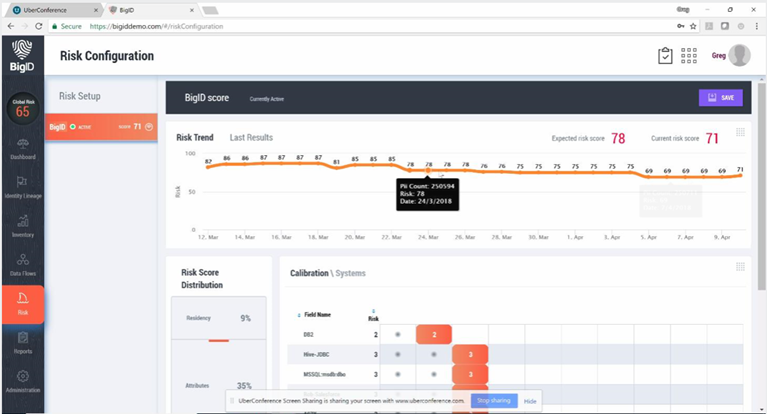
图:风险配置
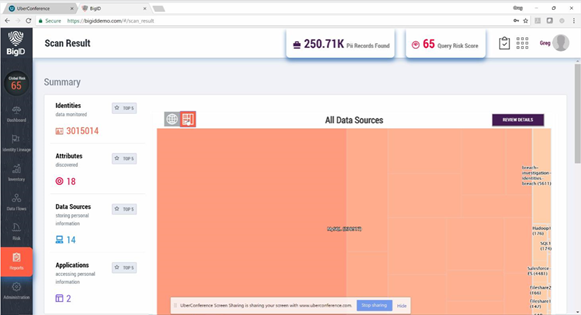
图:信息扫描结果
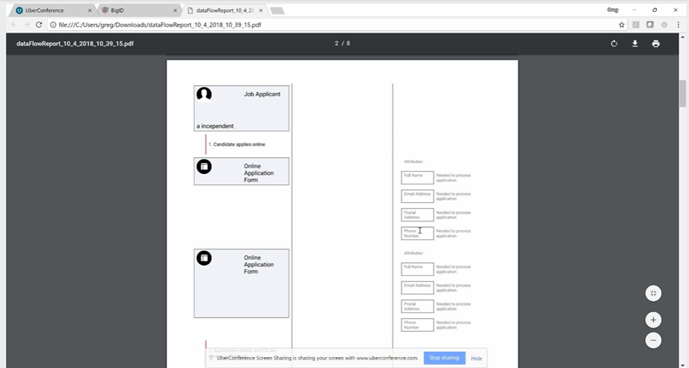
图:输出报告
笔者和BigID公司交流 解读数据沙盒技术
BigID公司的CEO Dimitri Sirota对外提到“想象我们是数据的谷歌,我们对数据进行检索归类,指出信息是属于哪个实体,数据的主体,但是它是虚拟的。我们不拷贝数据。它们仍保留在它们原有的地方”。笔者和BigID公司的Greg Pavlik进行了简单的交流,Greg Pavlik也展示和介绍了该公司产品的功能和界面,但对其技术细节没有更多的描述。
此外,BigID公司官网产品资料披露信息极少,因此结合该公司高管的发言和员工的交流介绍与demo展示,笔者初步分析猜测认为该公司产品是采用了一种称为数据沙盒(Data Sandbox)的技术,这个技术在大数据分析领域也有称为分析沙盒(Analytic Sandbox)。该沙盒技术不同于以往我们传统认知在防御入侵领域的沙盒技术。
在 入侵检测 领域,Sandbox 多为以虚拟方式模拟一个终端或一个运行环境,检测未知代码在该虚拟环境中的运行状况,并根据运行状况来判断其是否是怀有恶意。
在大数据领域,数据沙盒技术(Data Sandbox)是一种大数据分析应用手段。其原理是基于针对大数据分析的需要,不对原始数据进行拷贝和分析,仅搜索原始的结构化或非架构化的数据,形成新的数据信息仓库(data shadow warehouse)。然后根据事先定义的分析引擎去对提取的信息进行关联分析。数据沙盒技术并不算很新,多年前就已经出现,并在一些超大型跨国企业中得到了应用。
下面将对数据沙盒的特点和架构做一个简要的特点介绍和架构分析
数据沙盒的特点
- 数据沙盒会采用先进的BI(Machine Learning)和AI(Artificial Intelligence)技术帮助其对数据信息进行验证和分析
- 数据沙盒本身可以是一个独立的分析引擎凭条,也可以运行在Hadoop之上
- 实践中,数据沙盒多支持各种数据库以及多种数据结构,包括SQL数据库(如MSSQL,Oracle等)和NoSQL数据库(如MongoDB,Cassandra等)
- 数据沙盒允许分析引擎从多种大数据仓库中搜索各类数据。这些数据仓库可以是本地的,也可以是云端的。数据沙盒将搜索到的数据进行信息提取并以某种固定格式进行存储,最终形成一个虚拟的数据集市(data mart )
- 数据沙盒本身内置多种分析模型,这些模型多根据数据分析专家的需要(如商业情报或隐私保护)来进行编制。数据沙盒将根据这些分析模型对虚拟的data mart进行分析和结果呈现
- 数据沙盒的硬件设施包括大量的并行集中处理单元,高速内存,高性能存储和I/O接口能力。
数据沙盒架构展示
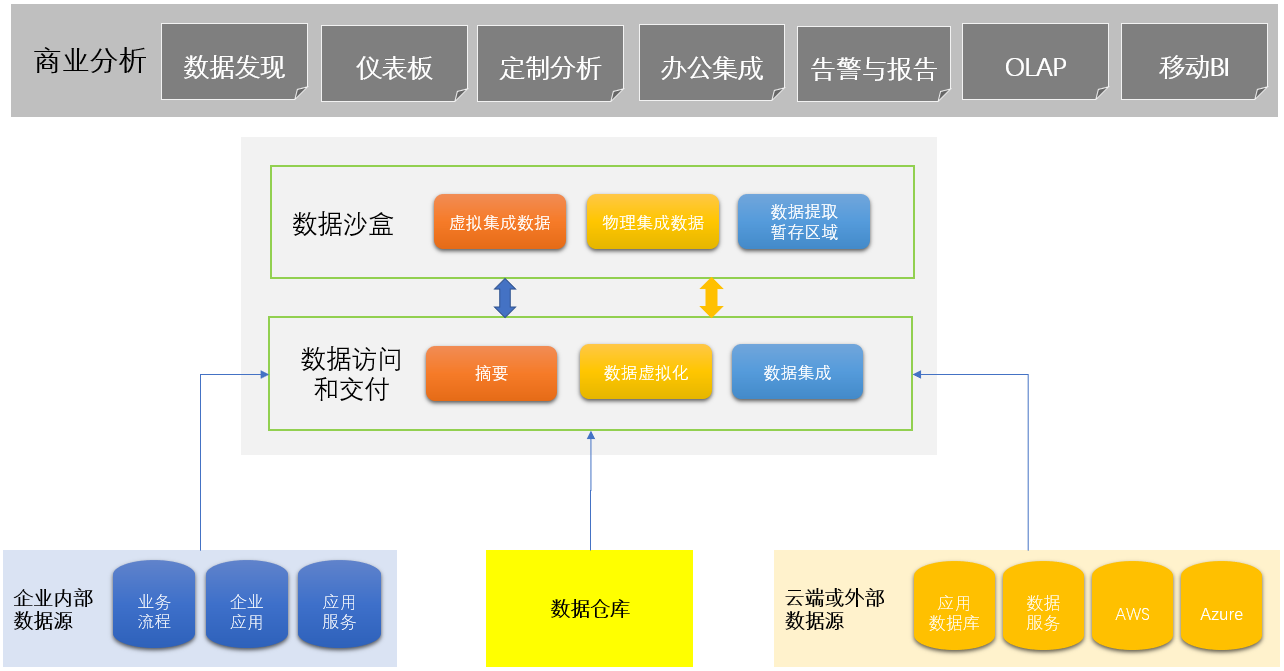
图:数据沙盒的原理架构设计
声明:本文来自安全加,版权归作者所有。文章内容仅代表作者独立观点,不代表士冗科技立场,转载目的在于传递更多信息。如有侵权,请联系 service@expshell.com。
 联系我们
联系我们 在线留言
在线留言 京公网安备11011202100645号
京公网安备11011202100645号