

Gartner提出了面向下一代的安全体系框架–自适应安全框架(ASA),该框架从预测、防御、检测、响应四个维度,强调安全防护是一个持续处理的、循环的过程,细粒度、多角度、持续化的对安全威胁进行实时动态分析,自动适应不断变化的网络和威胁环境,并不断优化自身的安全防御机制。
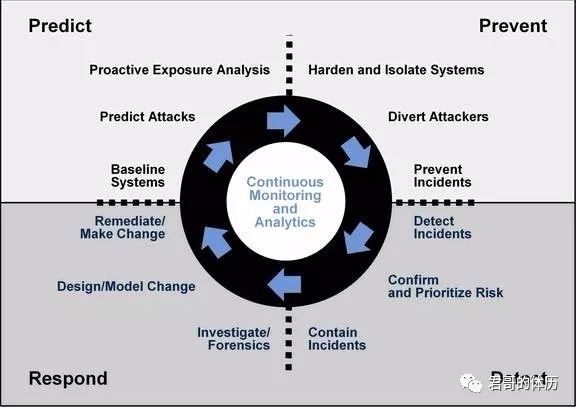
换另一种话来说,Gartner认为企业的安全问题或漏洞一定会不可避免的被外部发现并被人利用,那我们该如何更有效的进行应急响应呢?应急响应这个话题很容易就变成某机器被黑了上去敲一顿命令看日志检查后门,其实这里面还是有不少学问。
关于应急响应,首先是有针对性的国家标准可供参考,包括如下:
GB/T 24363-2009 《信息安全应急响应计划规范》
GB/Z 20985-2007 《信息安全事件管理指南》
GB/Z 20986-2007 《信息安全事件分类分级指南》
而针对金融行业,银监会还印发过《银行、证券跨行业信息系统突发事件应急处置工作指引》等。另外,还有一个PDCERF模型,将应急响应分为:准备(Preparation)、检测(Detection)、抑制(Containment)、根除(Eradication)、恢复(Recovery)、跟踪(Follow-up)六个阶段工作,分别如下:
-
准备:即在事件未发生时的准备工作,包括策略、计划、规范文档及具体的技术工具和平台
-
检测:初步判断是什么类型的问题,受影响的系统及严重程度
-
抑制:限制攻击、破坏所波及的范围,通俗的讲叫止血
-
根除:对事件发生的原因进行分析,彻底解决问题,避免再次在同一个问题上犯错
-
恢复:把业务恢复至正常水平
-
跟踪:针对事件的整改措施进行落实并监控是否有无异常,换句话叫安全运营中的持续改进
其次,有了这些标准、模型或指引,企业需要结合自身实际情况制定自己的应急响应规范,包括事件的分类分级、组织与职责、处理流程,甚至安全事件分析处理结果模板等。
GB/Z20986-2007《信息安全事件分类指南》根据信息安全事件的起因、表现、结果等,信息安全事件为恶意程序事件、网络攻击事件、信息破坏事件、信息内容安全事件、设备设施故障、灾害性事件和其他信息安全事件等7个基本分类,每个基本分类包括若干个子类。
-
恶意程序事件(计算机病毒事件,蠕虫事件,特洛伊木马事件,僵尸网络事件,混合攻击程序事件,网页内嵌恶意代码事件,其他有害程序事件)
-
网络攻击事件(拒绝服务器攻击事件,后门攻击事件,漏洞攻击事件,网络扫描窃听事件,网络钓鱼事件,干扰事件,其他网络攻击事件)
-
信息破坏事件(信息篡改事件,信息假冒事件,信息泄露事件,信息窃取事件,信息丢失事件,其他信息破坏事件)
-
信息内容安全事件(违反宪法和法律,行政法规的信息安全事件、针对社会事项进行讨论评论形成网上敏感的舆论热点,出现一定规模炒作的信息安全事件、组织串联,煽动集会游行的信息安全事件、其他信息内容安全事件)
-
设备设施故障(软硬件自身故障、外围保障设施故障、人为破坏事故、其他设备设施故障)
-
灾害性事件
-
其他信息安全事件
在企业内部,我们往往更多接触的是前几类,我们按实际情况结合自己的理解进行梳理后,分类如下:
一、针对互联网应用的攻击事件
互联网应用由于对外网开放,也最容易被黑客盯上,加上各种自动化的扫描工具的出现,每天系统会监测到各种各样的扫描请求,扫描器会尝试各种web漏洞请求如SQL注入、XSS攻击、上传漏洞、目录遍历、特定文件请求等;针对一些登录接口,黑客会进行暴力破解、撞库攻击;针对一些URL或API接口,黑客会针对性的遍历请求以获取更多信息;若进一步深入到系统中来,提权、安装后门、清理日志等也是会时有发生的;若这些都没成,黑客还有可能由于利益等采取DDOS攻击。
二、针对企业内网的攻击事件
企业员工一般都会有邮件、上网、U盘拷贝等渠道和外界保持联系,而这三个点也容易被外部攻击者利用。邮件里包含恶意文件,用户点击就被会被控制;用户可能访问的网页会包括漏洞挂马页面,用户访问就会中招;外部人员U盘插到内部电脑上也可能会引起机器被感染恶意程序等。恶意程序进入到企业内网之后,会进一步探测网络结构,寻找最有价值的攻击目标和系统,达成目标后可能会将需要的信息通过各种手段外传出去。近年流行的勒索软件则更简单粗暴,直接加密用户文档数据并要求受害者支付一定数量的比特币获取解密密钥。
三、来自内部的信息泄露事件
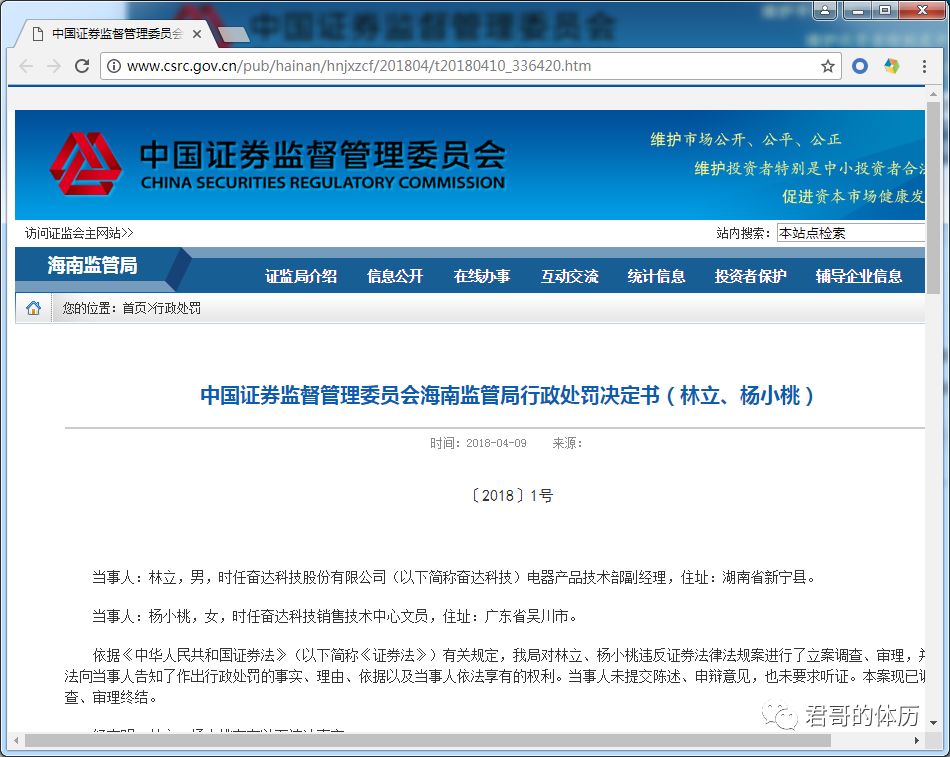
除了来自外部的攻击外,还有可能存在内部员工无意或有意的信息泄露事件。比如下面这起案例,源起一份文件遗忘在复制机台上被员工拍照发到朋友圈:
更多有意泄露的可能隐藏在背后,比如下面这个报道:

其实是腾讯联合京东发现黑产人员入职京东,后面进行了报案处理。随着事件的深入,该黑产人员被曝曾经入职多家互联网公司,这些公司的名单也开始在圈子里流传。
事件分级主要看受影响的系统重要程度及问题严重程度,很明显核心业务系统、边缘业务系统和非业务系统要区别开来,直接获取到系统权限、仅获取webshell权限、还是只是类似phpinfo信息泄露也完全不同。
准备工作
PDCERF模型第一阶段即是准备工作,包括应急响应的规范制度、具体技术工具和平台的搭建运营等。制度规范制订后需要真正能落实执行,靠模拟演练来提升处理效率。技术工具和平台有所区别,工具是类似于静态编译的ls、lsof、ps、netstat以及一些快速分析日志、扫描文件特征的脚本等,这些到了目标机器上就会发挥作用;而平台则是在企业部署了FW、NIDS、HIDS、WAF等系统后,将各种安全系统在终端、网络、应用上采集的日志集中送往到平台进行关联分析(如SOC系统)。
检测阶段
发生事件后,需要进行判断受影响的系统是什么,事件的性质是什么,这就是检测阶段。基于初步的分析结论,再采取不同的处理流程进行应急处置。如互联网某边缘系统被攻击在SOC系统上报警有扫描行为,可能就只需要运营人员简单拒绝就可以了,安全自动化做的好的企业可能就自动拦截了,不需要介入应急响应流程。进一步,这个边缘系统报警有执行敏感指令而且父进程属于web应用,可能就需要应急人员开始处置了,但是否上报,上报到哪个层级的问题,估计只是汇报给安全主管就可以了。再进一步,如果网银系统有大量撞库攻击事件同时有客户报障其账户因错误多次被锁,那只汇报给安全主管肯定不合适了。除了对业务的了解,还有一些技术含量的工作在内,比如流量大报警,是正常业务或发布导致还是有攻击,攻击是常规的DDOS还是CC还是机器被控制向外发包;再比如一封恶意邮件投递进来后,利用的是什么漏洞,回连地址是什么?
抵制阶段
有了前面的判断分析,出具针对性的止血措施,即是抵制阶段要做的工作。外网来的攻击,是封来源IP还是流量清洗,针对内网的攻击是在出口封堵还是在终端上干涉,都是执行层面的工作,日常多演练,尽量自动化,会极大的提升效率。
根除
针对事件进行根因分析,定位到真正的原因。比如前面说的这个边缘业务系统被人拿到webshell,对应的漏洞是什么,从日志分析试图还原出整个入侵轨迹,进而发现到底有什么漏洞,便于接下来的整改工作。
恢复
恢复正常业务,这个过程不再多述,前提是问题得到有效解决。
跟踪
往往发生安全事件,意味着安全系统不完善或者运营过程中存在失效情况,对事件进行根因分析,进而发现现有安全控制手段的缺陷,是一个很好的提升机会。比如前面WAF未拦截后面触发IPS报警,就可以针对性的优化WAF策略;比如某页面有手机号未做脱敏处理被外界发现,就可以针对性的发现从开发、测试到运维侧的各种问题,落实到安全运维上针对此信息泄露未能有效监测也是一个提升改进点。最后这些改进点,是否都落实到人,期限,是否有效?这就是需要本阶段要做的工作了。
最后,再说一点与应急响应本身无关的。在实际的工作过程中,会不会有这样的场景:监管收到一个关于某金融机构的漏洞而该金融机构本身却完全不知道,该会是怎样的一种体验?再试想,高层领导收到外部某安全公司的邮件说有你的机构有漏洞可能会被人利用,也会非常被动,除了自身在安全防御技术、运营上的努力外,还需要有一些其它层面的工作做,比如沟通、人脉、情报等等。互联网企业都建有自己的SRC,白帽子可以通过SRC平台报漏洞还有奖励,一方面借助白帽子发现企业漏洞进而提升企业安全性,另一方面减少漏洞被曝光在不可控平台的概率从而减少被动局面。
作者:一翔
声明:本文来自君哥的体历,版权归作者所有。文章内容仅代表作者独立观点,不代表士冗科技立场,转载目的在于传递更多信息。如有侵权,请联系 service@expshell.com。
 联系我们
联系我们 在线留言
在线留言 京公网安备11011202100645号
京公网安备11011202100645号