
Root 发自 凹非寺
去年5月,恶意勒索软件WannaCry大面积爆发,全球不少国家机构、企业、个人终端电脑中招,电脑文件被锁。
要想恢复重要资料,就必须向黑客支付300到600美元等值的比特币。
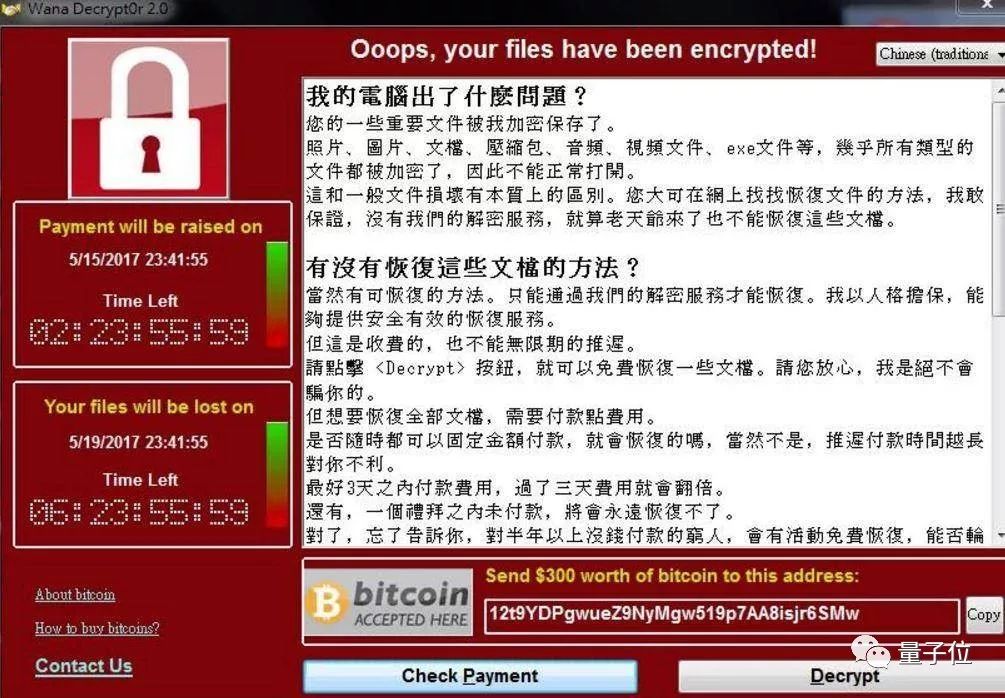
尽管微软早在去年3月14号就发布了针对该勒索软件所利用的漏洞的补丁,但不久又出来个Wannacry 2.0变种版本,导致更多电脑陷入魔爪。
由于勒索软件和僵尸网络不断“换马甲”,传统网络安全公司只能疲于奔命,被动地一一应付。考虑到AI强大的学习能力,擅长“以暴制暴”的黑客型网络安全公司Endgame想借助AI之力,帮助他们及时地识别出变种的恶意软件。

可是有个问题:目前缺少可供训练的数据集。
像图像识别或自然语言处理领域,都已经有庞大的开源的数据集来训练算法。但帮助AI识别勒索软件的数据集,还没有。
谁适合来做这件事呢?想来想去,拥有丰富防御黑客经验的Endgame决定自己上。
网络安全公司Endgame
其实,网络安全方面的数据从来都不缺。但因为数据总会涉及到个人的隐私,以及网络金融密码等信息,所以网络安全领域一直缺乏合适的数据集。
上周,Endgame宣布开源Ember(Endgame Malware BEnchmark for Research)数据集,其中含有杀毒软件VirusTotal 2017年检测到的110万个便携可执行文件(PE文件)的sha256哈希值,供研究恶意软件。
 为了避免泄露个人隐私,Endgame特地没有在Ember里放这些PE文件本身。但这个数据集包含元数据(metadata),也就是PE文件里提取出的特征,以及基于这些特征训练得出的基准模型。
为了避免泄露个人隐私,Endgame特地没有在Ember里放这些PE文件本身。但这个数据集包含元数据(metadata),也就是PE文件里提取出的特征,以及基于这些特征训练得出的基准模型。
有了开源的基准数据集之后,研究人员就可以量化AI技术的学习效果了。
关于数据
这110万个样本里,有90万个是用于训练的,剩下的拿来测试。
训练的样本里,恶意软件、无害软件、未标注软件的样本数相等,都是30万。测试样本里的恶意软件和无害软件等比。
每个样本都包含了PE文件的sha256哈希值,文件初次浏览月份,标注, 以及从文件提取出的特征。
从下图可以看出,训练数据和测试数据的比例。
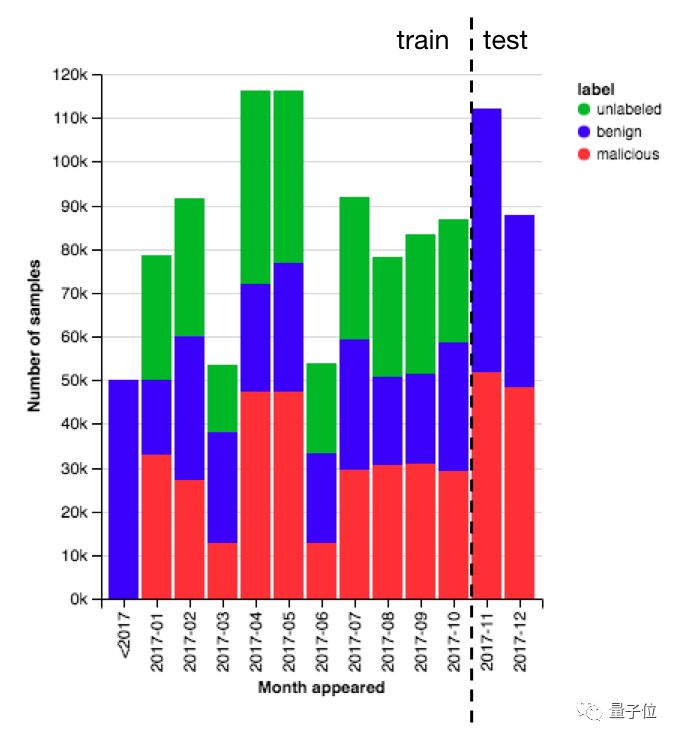
横坐标指代训练/测试时间段,这个信息对于随时识别“换脸”的恶意软件来说非常重要。这个数据集的目标,就是能识别出没有见过的恶意软件。
不过,公开这个数据集,Endgame要冒很大的风险。毕竟一旦公开之后,黑客也能接触到。训练样本被篡改后,识别模型就完蛋了。
除了数据,Endgame还在GitHub上建了一个储存库,方便大家使用这些数据。Ember库定义了基准模型的训练工作环境,大家也可以拿这些数据反复地训练模型。
Endgame还提供Jupyter notebook(https://github.com/endgameinc/ember/blob/master/resources/ember-notebook.ipynb),上面有模型表现的信息。代码里还特地有一段是定义特征的提取过程,详细介绍了如何从PE文件里算出特征。
有了这些资源,任何一个人都能下载到基准模型,然后用库重新分类新的PE文件。
关于模型
Ember基准模型,是一个梯度提升决策树(GBDT)。在默认模型参数的基础上,用LightGBM训练的。该模型在测试集的表现可以看下图。
对比二值分类器,一个比较好的方法是模型评估指标AUC。
Ember模型的测试成绩达到了0.9991123分。用同一个GBDT算法,也还有很多简单的办法提高这个分数,比方说优化模型的参数,进一步筛选特征,或者再提取出更好的特征。
Ember相当于一个测量参照,看模型训练的效果有没有不断靠近理想目标。

OMT
虽然挺好用的,但Endgame建议不要用Ember模型作为抗病毒的引擎。这只是个研究阶段的成果,和Endgame旗下成熟的产品MalwareScore还不一样。
Ember模型还没有更多地优化,也没有持续地更新数据,理论上来说没有现有的大部分防毒软件表现那么好。
Endgame模型的目的,是提供对比数据,也给未来的研究提供一个支撑点。
最后,Ember数据库的传送门:
https://github.com/endgameinc/ember
Endgame原文
https://www.endgame.com/blog/technical-blog/introducing-ember-open-source-classifier-and-dataset
论文:
https://arxiv.org/abs/1804.04637

△ 网上盛传的WannaCry的“进阶版”
声明:本文来自量子位,版权归作者所有。文章内容仅代表作者独立观点,不代表士冗科技立场,转载目的在于传递更多信息。如有侵权,请联系 service@expshell.com。
 联系我们
联系我们 在线留言
在线留言 京公网安备11011202100645号
京公网安备11011202100645号