
雷锋网 AI 科技评论按:当前的语音识别技术发展良好,各大公司的语音识别率也到了非常高的水平。语音识别技术落地场景也很多,比如智能音箱,还有近期的谷歌 IO 大会上爆红的会打电话的 Google 助手等。本文章的重点是如何使用对抗性攻击来攻击语音识别系统。本文发表在 The Gradient 上,雷锋网将全文翻译如下。

假设你在房间的角落放一台低声嗡嗡作响的设备就能阻碍 NSA 窃听你的私人谈话。你会觉得这是从来自科幻小说吗?其实这项技术不久就会实现。
今年 1 月,伯克利人工智能研究人员 Nicholas Carlini 和 David Wagner 发明了一种针对语音识别 AI 的新型攻击方法。只需增加一些细微的噪音,这项攻击就可以欺骗语音识别系统使它产生任何攻击者想要的输出。论文已经发表在 https://arxiv.org/pdf/1801.01944.pdf 。
虽然本文是首次提出针对语音识别系统的攻击,但也有其他例如针对图像识别模型系统的攻击(这个问题已经得到了不少研究,具体技术手段可以参考 NIPS 2017 图像识别攻防对抗总结),这些都表明深度学习算法存在严重的安全漏洞。
深度学习为什么不安全?
2013 年,Szegedy 等人引入了第一个对抗性样本,即对人类来说看似正常的输入,但却可以欺骗系统从而使它输出错误预测。Szegedy 的论文介绍了一种针对图像识别系统的攻击方法,该系统通过在图片(蜗牛图片)中添加少量专门设计的噪声,添加完的新图像对于人来说并未改变,但增加的噪声可能会诱使图像识别模型将蜗牛分类为完全不同的对象(比如手套)。进一步的研究发现,对抗性攻击的威胁普遍存在:对抗性样本在现实世界中也能奏效,涉及的改动大小最小可以只有 1 个像素;而且各种各样内容的图像都可以施加对抗性攻击。

这些攻击的例子就是深度学习的阿基里斯之踵。试想如果仅仅通过在停车标志上贴上贴纸就可能破坏自动驾驶车辆的安全行驶,那我们还怎么相信自动驾驶技术?因此,如果我们想要在一些关键任务中安全使用深度学习技术,那么我们就需要提前了解这些弱点还要知道如何防范这些弱点。
对抗攻击的两种形式
对抗攻击分为针对性攻击和非针对性攻击两种形式。
非针对性对抗攻击仅仅是让模型做出错误的预测,对于错误类型却不做干预。以语音识别为例,通常攻击完产生的错误结果都是无害的,比如把「I’m taking a walk in Central Park」转变为「I am taking a walk in Central Park」。
针对性对抗攻击则危险的多,因为这种攻击通常会诱导模型产生攻击者想要的错误。例如黑客只需在「我去中央公园散步」的音频中加入一些难以察觉的噪音,模型就会将该音频转换为随机乱码,静音,甚至像「立即打 911!」这样的句子。

花的爱拥还是死亡之萼?兰花螳螂是自然界中众多针对性欺骗的例子之一
对抗攻击算法
Carlini 和 Wagner 的算法针对语音识别模型的进行了第一次针对性对抗攻击。它通过生成原始音频的「基线」失真噪音来欺骗模型,然后使用定制的损失函数来缩小失真直到无法听到。
基线失真是通过标准对抗攻击生成的,可以将其视为监督学习任务的变体。在监督学习中,输入数据保持不变,而模型通过更新使做出正确预测的可能性最大化。然而,在针对性对抗攻击中,模型保持不变,通过更新输入数据使出现特定错误预测的概率最大化。因此,监督学习可以生成一个高效转录音频的模型,而对抗性攻击则高效的生成可以欺骗模型的输入音频样本。
但是,我们如何计算模型输出某种分类的概率呢?

通过算法推导出此音频片段中所说的词语并不容易。难点有如每个单词从哪里开始和哪里结束?
在语音识别中,正确分类的概率是使用连接主义时空分类(CTC)损失函数计算的。设计 CTC 损失函数的关键出发点是界定音频边界很困难:与通常由空格分隔的书面语言不同,音频数据以连续波形的形式存在。因为词汇波形之间可能存在许多「特征」,所以某个句子的正确识别率很难最大化。CTC 通过计算所有可能的输出中「期望输出」的总概率来解决这个问题。
Carlini 和Wagner 做出的改进
尽管这种初始基线攻击能够成功的欺骗目标模型,但人们也容易发觉音频被改动过。这是因为 CTC 损耗优化器倾向于在已经骗过模型的音频片段中添加不必要的失真,而不是专注于目标模型更难欺骗的部分。
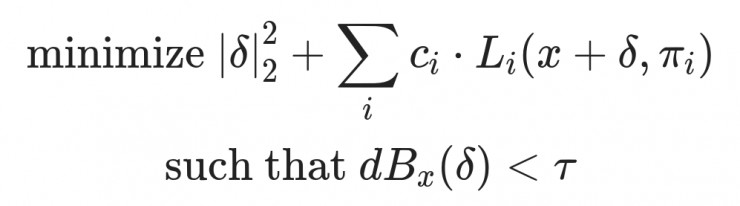
Carlini&Wagner 的自定义损失函数。π 是已计算特征,δ 是已学习对抗失真,τ 是最大可接受音量,ci是一个用于最小化失真并进一步欺骗模型的参数,Li 是第 i 个输出令牌的损失。
由于针对性攻击的最薄弱环节直接决定了攻击的强力与否,Carlini 和 Wagner 引入了一个定制的损失函数,该函数会惩罚最强攻击部分的不必要的失真。以基线失真为始,该算法会迭代地最小化该函数,在保持失真的对抗性的同时逐渐降低其音量,直到人听不到为止。最终的结果是音频样本听起来与原始样本完全相同,但攻击者可以使目标语音识别模型产生任意他想要的结果。
现实世界中的对抗攻击
尽管语音攻击令人担忧,但相比其它应用类型中的攻击,语音识别攻击可能并不那么危险。例如,不像自动驾驶中的计算机视觉技术,语音识别很少成为关键应用的核心控制点。并且语音激活控件可以有 10 秒左右的时间冗余,这段时间完全可以用来正确理解命令然后再去执行。
另外,对抗性攻击理论上可以用于确保隐私。比如制造一个设备,这个设备通过发出柔和的背景噪音使监控系统系将周围的对话误认为完全沉默。即使窃听者设法记录您的对话,但要从 PB 级的非结构化原始音频搜索出有用信息,还需要将音频自动转换为书面文字,这些对抗性攻击旨在破坏这一转化过程。
不过目前还并没有大功告成。Carlini & Wagner 的攻击在使用扬声器播放时会失效,因为扬声器会扭曲攻击噪音的模式。另外,针对语音转文本模型的攻击必须根据每段音频进行定制,这个过程还不能实时完成。回顾过去,研究者们只花费了几年的时间就将 Szegedy 的初始图像攻击发展的如此强大,试想如果针对语音的对抗性攻击的发展速度也这么快,那么 Carlini 和 Wagner 的研究成果着实值得关注。
雷锋网 AI 科技评论认为对抗性攻击可能会利用深度学习的算法漏洞进行破坏,引发诸如自动驾驶等应用的安全问题,但如上文所述,针对音频的对抗性攻击对于隐私保护也有积极意义。
via thegradient.pub,雷锋网 AI 科技评论编译
声明:本文来自雷锋网,版权归作者所有。文章内容仅代表作者独立观点,不代表士冗科技立场,转载目的在于传递更多信息。如有侵权,请联系 service@expshell.com。
 联系我们
联系我们 在线留言
在线留言 京公网安备11011202100645号
京公网安备11011202100645号