
文 / 中国人寿保险股份有限公司研发中心
向玲 徐征 阮强 张旌
随着洗钱犯罪日益复杂化、多样化,国内外反洗钱监管形势也日趋严峻,保险业反洗钱工作面临更大挑战,急需利用新技术丰富和完善反洗钱监测手段。本文将介绍如何利用人工智能技术建立反洗钱智能监测模型,提升反洗钱工作的有效性。
人工智能技术在反洗钱领域的应用可以有3个场景,即:可疑交易识别、可疑交易分析、外部信息调查。保险公司可以充分利用自身的海量交易数据、互联网数据,结合保险业洗钱行为特征,采用机器学习/深度学习、知识图谱、自然语言处理等人工智能技术,对日常交易进行监测,识别出“合理怀疑”交易及个人,进行智能查证分析,确认或排除可疑。因此,反洗钱监测模型由3部分组成:反洗钱可疑交易智能识别、反洗钱知识图谱智能分析、外部信息智能搜索。
反洗钱可疑交易智能识别,提升识别有效性
保险业反洗钱可疑交易智能识别的基本做法是基于保险交易数据提取反洗钱特征、采用适合的机器学习/深度学习算法,基于历史交易数据进行训练,得到智能监测模型,再用该模型对新增交易做出可疑程度的判断。保险业反洗钱智能识别模型在建立与迭代优化过程中体现出以下几个特点。
反洗钱智能识别适合采用无监督学习算法。从数据角度,保险业并没有积累起多少“真正类”数据,即经过确认的洗钱线索与案例。退一步,如果以“合理怀疑”作为学习目标,即以向央行报送的可疑交易作为标注数据,同样存在正类数据极少、很难开展有监督学习的问题,因此,反洗钱领域的学习训练如果阳性数据不足,最好采用无监督学习方法。
在模型建立过程中,经过多次尝试比较,我们最终选择了孤立森林算法用于学习训练。孤立森林是一个基于Ensemble的快速异常检测方法,具有线性时间复杂度和高精准度,是符合大数据处理要求的算法,其基本原理是:在数据空间里面,分布稀疏的区域表示数据发生在此区域的概率很低,因而可以认为落在这些区域里的数据是异常的。该算法效果较好,时间效率高,能有效处理高维数据和海量数据。
特征选择是模型能力的决定性因素。一方面,特征选择决定模型性能。一般来讲,特征决定模型上限,算法的性能将最终取决于特征。保险公司积累了海量数据,但这些数据大多是自然属性类数据,对交易与客户的刻画是“模糊”的,对业务规律的揭示能力有限。同时,保险交易属于低频交易,交易类数据较少,且缺乏关联,这也制约了风险特征的选择与构建。如何结合保险业特点,深入分析洗钱犯罪规律,从基础信息出发,构造出与洗钱相关的行为关联、时间关联的衍生特征,成为模型成败的关键。在我们的实践中,从反洗钱业务规律出发,从交易、客户、第三方交易人3个维度,构建了上百个衍生特征,以此刻画洗钱可疑交易,比如短期内的特定交易、投退保、借还款等行为。
另一方面,特征选择决定了模型是否是反洗钱的识别模型。异常检测与具体的应用场景密切相关,模型需求确保算法检测出的“异常”就是我们想要的、反洗钱的异常,离群点的“群”一定就是从反洗钱角度正常的“群”。因此,在特征选择时,需要对反洗钱业务规律深入分析,从而过滤掉与反洗钱无关的特征。
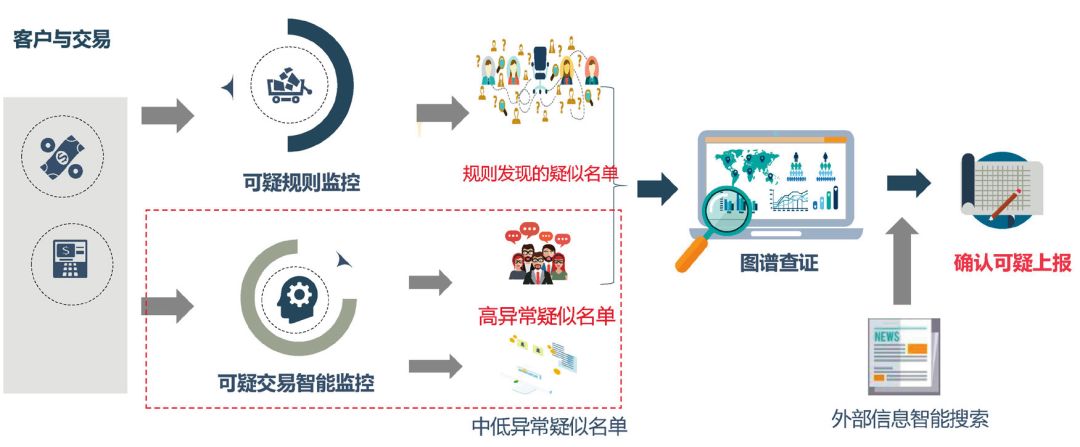 图 反洗钱智能监测模型框架
图 反洗钱智能监测模型框架
此外,算法超参数调优、选择适合的抽样技术、采用分布式计算还是单机计算等,都可能影响模型性能,这里不再赘述。
从业务和技术两个维度度量模型效果。有监督学习的模型度量是清晰的,可以采用与标注数据对比得到明确的度量指标,而无监督学习的模型度量是一个难点。在我们的实践中,采用了技术和业务两个维度的度量来确保模型效果。
业务视角的度量有两种,一是,尽管以“合理怀疑”为标准的标注数据很少,但仍可以用作模型的迭代优化。在传统的基于规则识别可疑的工作模式中,大致的数量关系是,规则触发可疑:上报可疑=1000:1,也就是规则触发1000笔可疑交易,最终认定1笔可疑上报。在智能检测模型的输出结果中,所有上报的可疑交易出现的位置越靠前,效果越好。第二种业务度量是,是否有大量规则未能识别的可疑交易出现,以及,排名靠前的交易在排查时是否真的被人工判断为“合理怀疑”程度较高。
纯技术的验证方式则是采用了自编码(auto-encoder)的深度学习算法用于模型验证。自编码是将样本进行压缩降维、再解压还原的深度学习算法,我们将这一算法灵活运用作为孤立森林算法模型结果的验证方法。
反洗钱知识图谱智能分析,增强查证有效性
知识图谱是人工智能的一个重要分支,把所有不同种类的信息连接在一起而得到的一个关系网络,以“关系”展示“实体”间的关联,提供了从关系角度去分析问题的能力,通过关系推演,挖掘隐藏的“实体”间关系,从而扩展知识,掌握关键信息、发现隐含线索。
引入图存储与图计算能力,实现对海量数据的分析和探索。保险公司在长期的经营中积累了海量数据,这些数据往往分散在各个业务系统中,形成一个一个的信息孤岛。知识图谱可以帮助我们从各种类型的数据源中提取模型需要的实体、属性以及实体间的相互关系,进而形成知识。获得知识后,还需要对知识进行整合,消除实体间的矛盾与歧义,以确保知识库的质量。在我们的研究实践中,可以将所有相关系统的数据按照实体、属性和关系整合在一个平台,从而实现了对海量数据的分析和探索。
构造反洗钱相关图谱、挖掘隐性关系。在我们的研究实践中,构建了客户、账户、交易等主要实体,提炼了反洗钱相关的典型、特定业务行为作为事件,实现了从客户关联人、关联保单及关联账户等3条线索的深度挖掘,实现了资金流向及归集的挖掘与展示,实现了客户、账户隐性关系的计算和展示,从而帮助我们发现洗钱线索。
利用图形化、可视化技术,实现实体之间的关系展现。可以充分利用知识图谱工具的图形化、可视化功能,结合反洗钱业务规律,将反洗钱业务分析经验固化为分析模式展现在分析平台上,在我们的研究实践中,可以做到信息操作一站实现、常规查证一键完成、隐性关系一目了然,专家模式一查到底。
外部信息智能搜索,辅助反洗钱查证
反洗钱尽职调查中需要尽可能获取调查对象的相关信息,人工智能技术在这一领域有两方面的应用,一是利用RPA(机器人流程自动化)技术自动抓取查证所需互联网信息,并自动下载呈现,供反洗钱工作人员参考。在实际工作中,企查查、天眼查等网站的信息获取可以采用这样方式。二是用智能搜索和自然语言处理/生成技术获取和整理互联网信息,从实践来看,一定比例的个人、较大比例的企业可以在互联网上搜索到有参考价值的信息,当然,这些信息只能作为发现线索的参考,不能作为定性的证据。
预期效果
从初步研究与实践结果看,反洗钱智能监测模型可以显著提高可疑交易识别的精准度,从业务角度衡量,与规则模式相比,可疑上报基数缩小10倍以上,这就意味着,如果以智能识别替代规则识别模式,可以减少约10倍的人工调查作业量。同时,基于知识图谱的分析平台也将大量节省查证的人工作业量,整体提高查证分析水平。外部信息的辅助查证也将提高查证的有效性。
同时,反洗钱智能监测模型的研发,将有效丰富保险业反洗钱工作手段,有效提升风险防范水平,在坚决打赢防范金融风险攻坚战的总要求下,对于提升保险业的行业形象具有积极意义。
声明:本文来自金融电子化,版权归作者所有。文章内容仅代表作者独立观点,不代表士冗科技立场,转载目的在于传递更多信息。如有侵权,请联系 service@expshell.com。
 联系我们
联系我们 在线留言
在线留言 京公网安备11011202100645号
京公网安备11011202100645号