
一、边缘计算发展概述
随着物联网产业及技术的快速发展,边缘计算架构愈发得到各大厂商的关注。Gartner预测,从2017年到2021年,将边缘计算纳入项目范围的大型企业数量比例,将从不到1%增长到40%。IDC则预测到2020年,物联网所有支出的18%将被边缘计算所覆盖,到2022年,边缘计算支出将可达到2160亿美元。面对如此庞大的市场规模,各大CT通信企业以及IT互联网企业,都已开始积极的技术积累与产业布局。这其中,传统云计算巨头如亚马逊、微软、谷歌,基于云计算方面的技术优势,率先加入边缘计算概念的落地实现中,期待将云端能力拓展到网络边缘,形成云边端全链路覆盖的整体解决方案。
简单的回顾计算模型的发展历史,从集中式处理的IBM大型机,到个人计算机的普及,再到并行与分布式计算的大规模发展,最终从网格计算演化到云计算,计算模型经历了集中式、分布式的迭代式的演进过程。主流计算模型的演化是计算机技术与互联网、通信产业发展共同作用的结果。云计算通过虚拟化、分布式、容器等相关模型、技术的积累与按需付费等商业模式的支撑,为用户提供了集中式的计算、存储、通信等各类资源,开发平台以及原生服务,现阶段,已成为互联网产业的最重要组成之一。
然而,云计算的云端属性,决定了完全依赖云服务将面临多种挑战。首先就是处理实时性的问题。目前互联网网络基础设施的发展速度,可以说难以匹配用户,无论是企业用户还是个人用户的实时响应需求。高处理延迟一方面可能是云端计算任务的批量化导致,另一方面,不稳定的网络环境很大程度上限制了处理结果的响应速度。其次,智慧城市、工业互联网、智能终端的爆发式增长,直接推动了互联网流量以及数据量的暴增。
大规模数据的处理如果完全依赖云端资源,数据的传输对网络带宽将产生巨大的冲击,购买带宽的花费也是用户所难以接受的。最后,隐私保护和数据安全性也成为云端数据处理的一个重要限制。在相关法律法规没有完全成熟健全的情况下,许多涉及企业机密、用户隐私的数据,上传到云端、云端进行分析、云端存储等多个环节,都面临数据被窃取、篡改、丢失的隐患,这导致用户对云端数据的处理产生不少的疑虑。
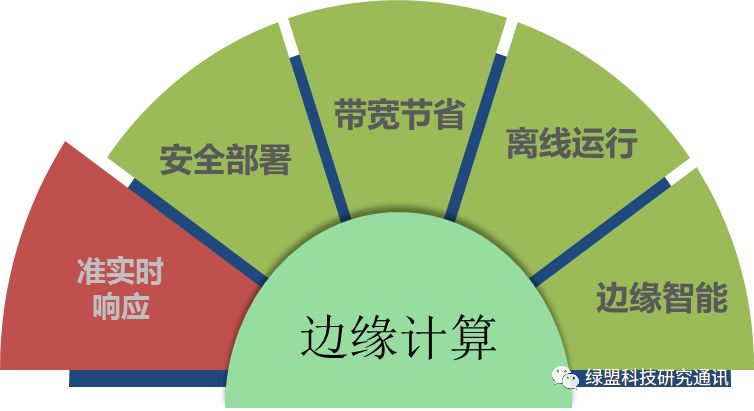
因此,针对以上多个问题,弥补、拓展云端处理能力的不足,边缘计算的概念逐渐火热起来。本质上来讲,云计算加边缘计算的架构模型,是数据分层处理的直接体现。CDN、智能处理基站、边缘侧数据中心等等基础设施和技术方案,都是在完善、拓展云端能力到边缘侧。只是在当前5G、物联网、智能终端高速发展的大环境下,愈发需要体系化的边缘计算解决方案,从功能架构、计算实时性、任务调度、安全性、智能化、云边协作方式等多方面,整合边缘资源,将云端、边缘、端设备的全链路数据处理流程打通。
现阶段,微软的Azure IoT Edge、华为的KubeEdge边缘侧解决方案相继开源,亚马逊的AWS Greengrass(以下简称AWS GG)、谷歌的Edge TPU和Cloud IoT Edge、VMware Pulse IoT Center等架构也在不断更新,一场边缘计算市场的争夺战悄然展开。
二、基于AWS GG的机器学习模型部署实践
“AWS Greengrass是一种允许您以安全方式在互联设备上运行本地计算、消息收发、数据缓存、同步和ML Inference功能的软件。借助AWS Greengrass,互联设备可以运行AWS Lambda函数、同步设备数据以及与其他设备安全通信——甚至无需连接互联网。通过使用 AWS Lambda,Greengrass可以确保您的IoT设备能够快速响应本地事件,使用正在 Greengrass Core上运行的Lambda函数以与本地资源进行交互,执行间歇性连接,通过无线更新保持更新状态,最大限度地降低将IoT数据传输到云的成本。”
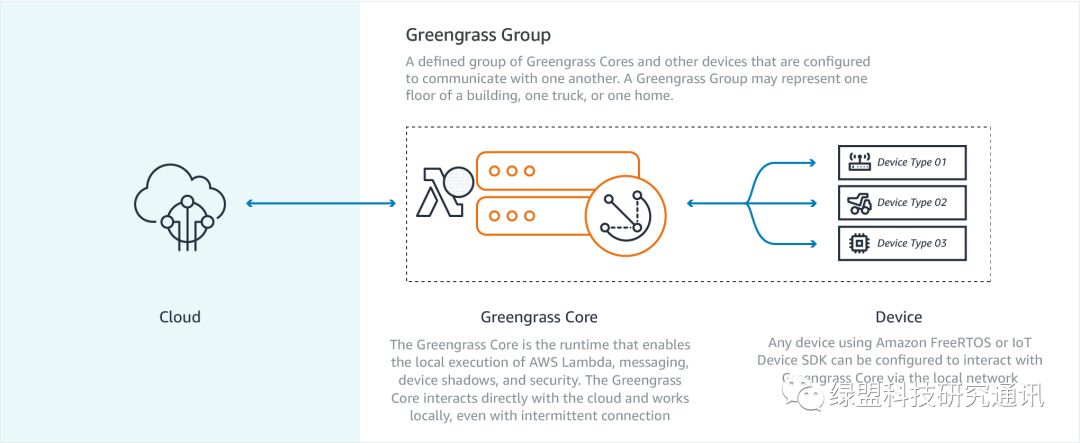
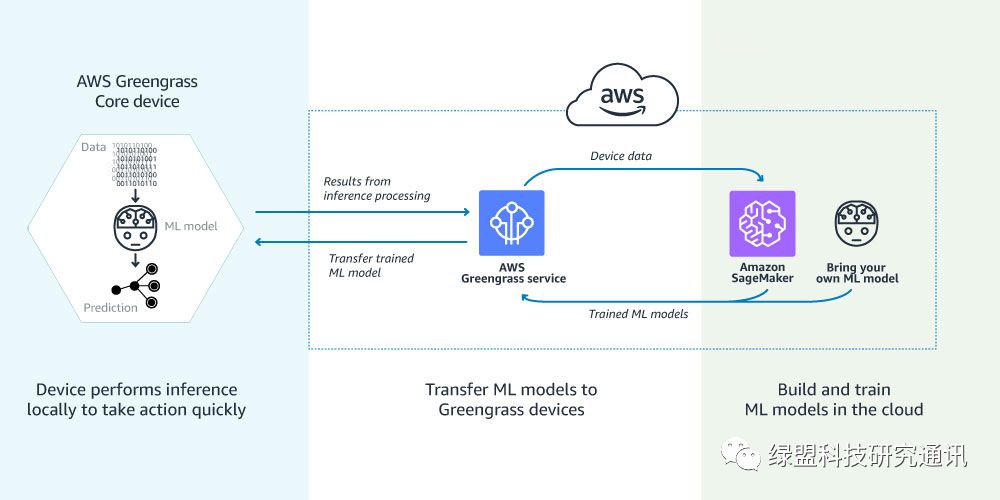
以上是AWS GG官网的介绍。从特性上来讲,AWS GG主要支持准实时的本地事件响应以及脱机运行,安全通信机制以及通过AWS Lambda实现的设备编程。从架构上来看,AWS GG边缘侧由Greengrass Core以及基于AWS GG SDK开发的设备(Device)构成。Greengrass Core是边缘侧的核心部件,能够完成在本地执行AWS Lambda函数,并管理消息收发、数据缓存和安全策略的等功能。
本节将实现,基于AWS GG在边缘设备上部署机器学习模型,并在边缘侧完成分类任务,将结果回传到云端进行展现。
1、环境搭建
首先,按照AWS官网教程搭建Greengrass环境(参考:https://docs.aws.amazon.com /greengrass /latest/ developerguide/gg-gs.html)。本次部署中,主要包括两部分:
-
AWS云端环境:AWS 账户、EC2主机、IAM账户
-
AWS GG Core(核心):可部署在本地主机(Greengrass支持的环境即可,具体可在以上官网链接查询)或者AWS EC2主机上
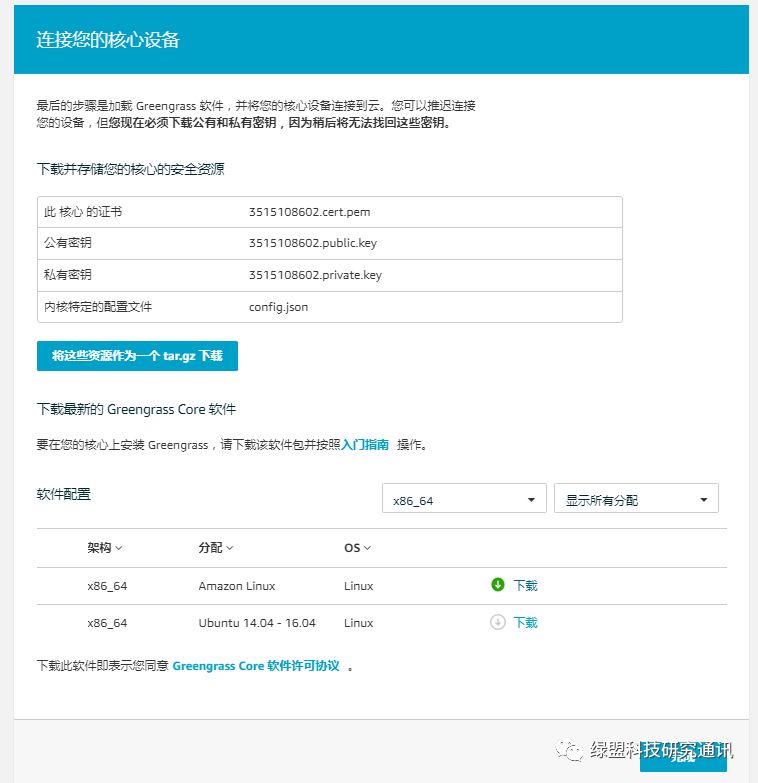
本实验中,部署了两种核心设备,分别是本地虚拟机(Ubuntu 16.04 server, python 2.7)和AWS EC2 Amazon Linux(x86-64, python 2.7)主机。核心设备上需要部署的资源包括证书和核心软件等:
Tips1:仅测试Greengrass Core功能建议将核心软件部署在EC2主机上。在较差的网络环境下,本地部署的Greengrass核心与云端通信可能有较大延迟,导致功能部署周期过久。
Tips2:AWS部署的任何服务实例有区域之分,Greengrass目前支持的区域相对少。选择区域需要考虑业务支持、速度等因素;同时需要保证所需的各个服务在一个区域中:一方面保证服务之间的连通性(如AWS IOT与S3之间、EC2与S3之间),另一方面同区域之间数据传输大概率是免费的。建议选择us-east-1(US East N. Virginia)
2、基于AWS GG Core的机器学习程序开发
a) AWS Lambda简介
Lambda是AWS的无服务计算的核心概念,又称为`FaaS’,即Function as a Service。AWS GG通过在核心上部署Lambda函数来执行任务代码。Greengrass Core的软件是闭源的,其中包含了Lambda运行时环境。Lambda将程序所需的资源进行了自动化封装,对用户透明,减少了用户对底层环境的配置、开发工作。在Greengrass Core上部署的Lambda函数会在Greengrass Core软件提供的容器或者沙箱环境下执行。
b) Greengrass Lambda包创建
开发和在AWS GG Core上部署Lambda函数,主要分为以下4个步骤,本节介绍步骤1。
1. 创建部署包;
2. 上传部署包;
3. Greengrass部署;
4. 测试Lambda功能
Lambda函数主要有两种实现类型,一种不依赖AWS提供的SDK之外的高级程序包;另一种则依赖于其他高级程序包。对于第一种,只需要将基于AWS GG SDK编写的业务代码与AWS提供的对应SDK打包即可;对于第二种,则需要安装程序依赖的各种库,本次部署属于此类。
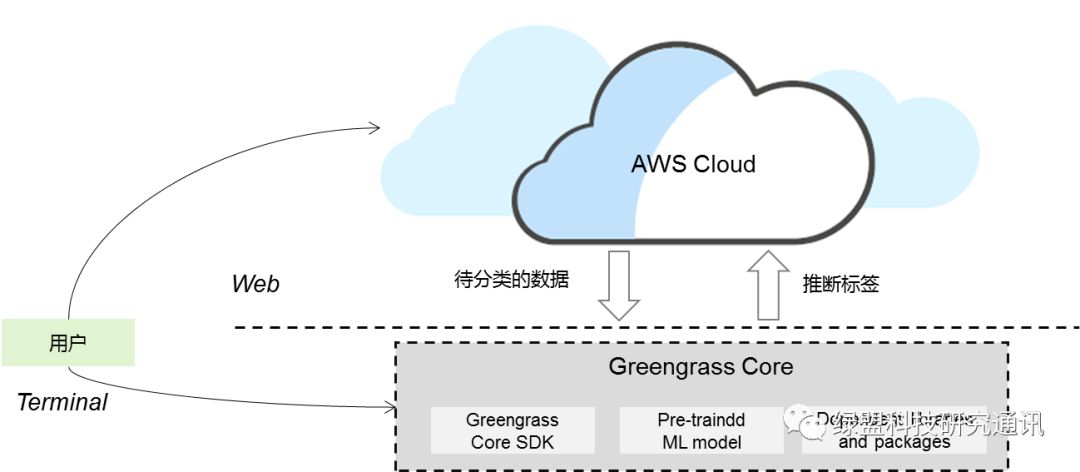
Lambda函数可以在云端开发并部署,也可以在本地开发,将程序打包上传到云端。本次实验采用本地创建机器学习模型并上传部署的方式。具体的应用部署拓扑见上图,实验目的是将待分类数据实例特征传输到Greengrass核心,Greengrass核心通过部署的机器学习模块进行推理,得到分类结论并传输回云端显示。实验训练和测试数据来源于iris数据集(https://archive.ics.uci.edu /ml/datasets/iris)。
本实验所需具体步骤可参考:
1. 在指定目录下,通过virtualenv创建虚拟环境和greengrassHelloWorld子目录;
cd my_project
virtualenv my_project_envsource my_project_env/bin/activatemkdir greengrassHelloWorld
2. 将Greengrass Core SDK、用户程序、训练数据移动到greengrassHelloWorld目录。其中,用户程序包括模型训练程序和需要打包到Lambda函数并包含机器学习模块的推理模型程序两部分;
3. 安装用户程序所依赖的程序包安装到工作目录;
pip install module-name -t /path/to/my_project-dir
以本实验所需安装模块为例,需执行以下命令,将外部依赖库安装到当前目录:
pip install pandas -t .
pip install numpy -t .pip install sklearn -t .pip install cPickle -t .
最终,用户程序主要依赖的程序库包括:
l Greengrass Core SDK包含的:
import greengrasssdkimport platformfrom threading import Timerimport timeimport json
主要依赖的外部包:
import pandas as pd
import numpy as npfrom sklearn.neighbors import KNeighborsClassifierimport cPickle
4. 本地执行模型训练程序。该程序不需要引用greengrasssdk,只需要按照创建机器学习模型的基本步骤,训练模型,并生成模型文件my_model.pkl。pkl文件是通过cPickle生成的持久化模型文件,推理模型程序中需要通过cPickle模块加载该模型文件;
5. 打包所有程序、SDK、依赖包为.zip文件。
值得注意的是,所有文件大小已超过300M,打包后为67M。
Tips1:须在包含所有库文件、SDK、程序文件的目录内直接打包,而不是打包外部的文件夹。
Tips2:最新版本的Greengrass Core SDK中缺少本地编译所需要的两个库greengrass_common和greengrass_ipc_python_sdk(实际上包含在Greengrass Core运行时软件中),可在以下链接获取https://github.com/dzimine/greengo。
Tips3:本例中模型训练程序与greengrass解耦,即无需加载greengrasssdk,只需要生成推理程序可以加载的模型文件(.pkl等)即可;推理模型程序基于greengrasssdk中的greengrassHelloWorld程序,通过改写消息处理函数function_handler执行云端消息的处理,相关程序请见下节。
c) 附录:模型训练程序和推理模型程序示例
模型训练程序(gg_ml_train.py):
import pandas as pd
import numpy as npimport cPicklefrom sklearn.preprocessing import LabelEncoderfrom sklearn.feature_extraction import DictVectorizerfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifier# data loadingdf = pd.read_csv("iris.csv")# data preprocessinglabels = np.asarray(df.species)le = LabelEncoder()le.fit(labels)# apply encoding to labelslabels = le.transform(labels)df_selected = df.drop(["species"], axis=1)df_features = df_selected.to_dict(orient='records')vec = DictVectorizer()features = vec.fit_transform(df_features).toarray()# partition data setfeatures_train, features_test, labels_train, labels_test = train_test_split( features, labels, test_size=0.20, random_state=42)# initializeclf = KNeighborsClassifier(n_neighbors=3)# train the classifier using the training dataclf.fit(features_train, labels_train)# save the classifierwith open('NN_classifier.pkl', 'wb') as fid: cPickle.dump(clf, fid)
推理模型程序(gg_ml_predict.py):
import pandas as pd
import numpy as npimport cPicklefrom sklearn.preprocessing import LabelEncoderfrom sklearn.feature_extraction import DictVectorizerfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifier# data loadingdf = pd.read_csv("iris.csv")# data preprocessinglabels = np.asarray(df.species)le = LabelEncoder()le.fit(labels)# apply encoding to labelslabels = le.transform(labels)df_selected = df.drop(["species"], axis=1)df_features = df_selected.to_dict(orient='records')vec = DictVectorizer()features = vec.fit_transform(df_features).toarray()# partition data setfeatures_train, features_test, labels_train, labels_test = train_test_split( features, labels, test_size=0.20, random_state=42)# initializeclf = KNeighborsClassifier(n_neighbors=3)# train the classifier using the training dataclf.fit(features_train, labels_train)# save the classifierwith open('NN_classifier.pkl', 'wb') as fid: cPickle.dump(clf, fid)
3、Greengrass Core程序部署
Greengrass Core程序在本地打包好后,需要作为源文件上传到云端,构造Lambda函数。具体过程可参见官网教程,具体细节不在此介绍,其中有几个问题需要注意。
a) 程序包的上传
创建Lambda函数需要上传程序包,目前支持三种方式:在线编辑、通过zip上传、通过AWS S3服务传输。其中,在线编辑适合较为简单的任务;通过zip上传有50M的上传文件大小限制。此外,所上传.zip文件加压后不能大于250M。否则上传会报错:
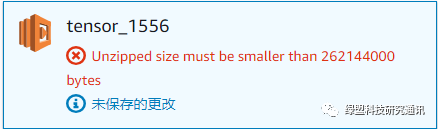
所以需要控制所创建的程序压缩包的大小。本实验生成的.zip文件大小已超过50M,都通过s3服务上传。
Tips1:建议通过EC2实例增量更新用户程序,并在EC2实例内打包。打包后的.zip文件通过aws s3 sync或者aws s3 cp命令上传到s3,通过这种方式能够大幅度降低程序包上传的时间。
b) Lambda函数配置

以上是代码配置界面的,值得注意的是,处理程序处需要准确填写用户程序模块名和用户定义的消息处理入口函数,以本实验为例,需填写:
gg_ml_predict.function_handler
c) Lambda函数部署主要流程
按照官方教程,主要包含以下几个步骤:
1. 创建Lambda函数:
-
上传代码
-
发布版本
-
编辑Lambda参数
2. 添加Lambda函数到Greengras组
3. 添加消息订阅规则;
4. Lambda函数部署。
由于lambda函数是事件驱动的运行模式,因此消息订阅规则确定了Greengrass组内(包含AWS IoT云端、Greengrass Core以及AWS IoT Device)内的信息传递路径,需要根据业务流程进行设计。
4、Greengrass Core程序测试
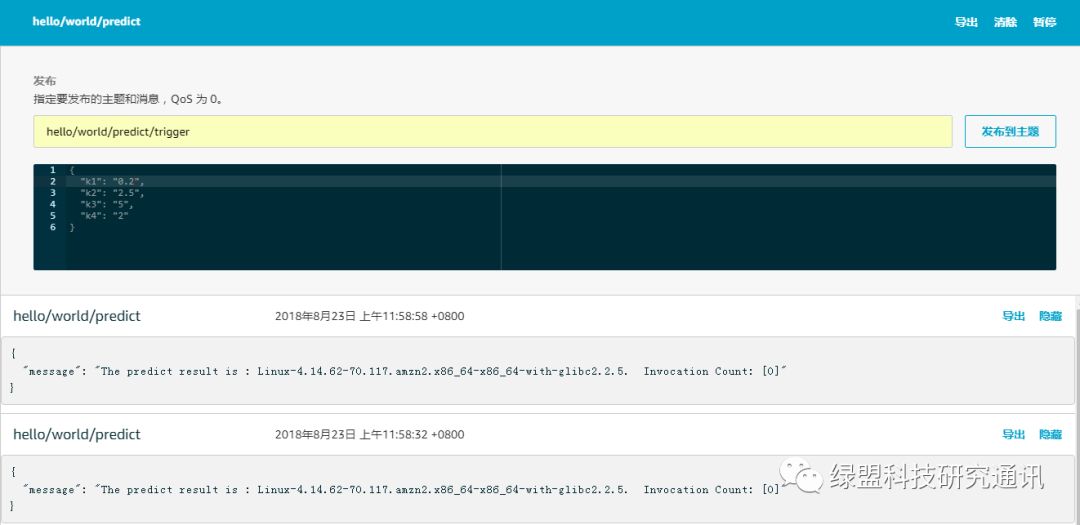
由于本地设备与AWS云端通信的时间开销较大,导致本地部署实验的调试周期过长,因此本实验选择测试AWS云端与EC2主机上部署的Greengrass Core之间的任务部署。可通过AWS GG测试环境,对部署的Lambda函数进行测试,可实现通过云端将消息发送到Greengrass Core订阅的消息组,并接收来自边缘的结果消息。测试页面示例如下:
5、Greengrass Core程序调试
按照上述步骤创建的开发环境,可调试和测试除了Lambda机制之外的用户定义程序部分,如机器学习模块。建议本地调试、测试ML模块(或其他功能模块)之后,上传代码部署Lambda函数进行Greengrass Lambda测试。
Lambda部署测试过程中,在Greengrass Core上部署的Lambda函数,可通过以下目录查看程序运行日志(需要root权限):
path_to_greengrass/ggc/var/log/user/
其中path_to_greengrass是greengrass core安装的文件目录。
6、Greengrass Core TensorFlow应用开发部署
前述章节部署和测试了基于scikit-learn的应用,本节关注TensorFlow应用的部署。由于Greengrass Core上传部署的.zip应用包解压后不能大于250M(这是AWS Lambda函数的限制),所以在TensorFlow应用部署中发现诸多问题,记录如下。
a) TensorFlow安装
如前述章节类似,可通过virtualenv命令在指定目录下安装TensorFlow库文件。本次实验中,使用了1.5版本的TensorFlow。安装命令参考如下:
mkdir gg_tf_test
cd gg_tf_testsudo pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow==1.5 -t .
安装后,import tensorflow报错:ImportError: No module named google.protobuf,此时,需要在google目录下新建一个空的__init__.py文件。
touch google/__init__.py
b) MNIST应用本地测试
本节测试MNIST手写体图像识别应用,仍然通过AWS GG云端提供的测试界面。目标是从云端发送一个0~9的index编号,greengrass核心收到此消息后,将其当前目录下对应编号的图片的识别结果发送回云端。其中,所使用的开源MNIST识别项目为:https://github.com/golbin/TensorFlow-MNIST。测试过程中主要问题及解决:
- 依赖问题,ImportError: No module named PIL。解决:
pip install Pillow -t .
-
应用部署到Greengrass核心上之后报错:[ERROR]-lambda_runtime.py:170,Handler function failed with exception: Variable W1 already exists, disallowed. Did you mean to set reuse=True or reuse=tf.AUTO_REUSE in VarScope?解决:参考以下代码,https://www.tensorflow.org/api_docs/python/tf/get_variable,对相关变量引用加入重用参数:
def foo():with tf.variable_scope("foo", reuse=tf.AUTO_REUSE): v = tf.get_variable("v", [1]) return v
c) TensorFlow应用尺寸剪裁
AWS Lambda函数内部署的应用程序包的大小不能超过250M。而使用pip安装的TensorFlow的相关库文件大小已超过300M:
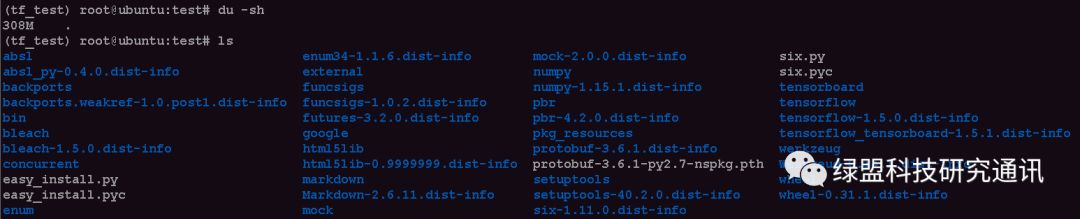
AWS GG官方有提供预编译的Apache MXNet (Apache 许可证 2.0)、TensorFlow、(Apache 许可证 2.0)和Chainer (MIT许可证)的预编译库,但目前只支持NVIDIA Jetson TX2、Intel Atom和Raspberry Pi平台,未支持其他通用平台。因此,本地打包的相关应用必须自行剪裁。目前使用了以下两种方式:
-
使用strip命令缩小.so库文件尺寸,主要针对TensorFlow安装目录下的tensorflow和python文件夹,可参考一下代码:
find path-to-cut/ -name "*.so" | xargs strip -
删除不必要的文件和库,如:
external/setuptools/tensorboard/werkzeug/html5lib./tensorflow/include/unsupported./tensorflow/include/Eigen
经过以上剪裁,打包前的文件大小略小于250M,最终支持在Lambda上的部署:
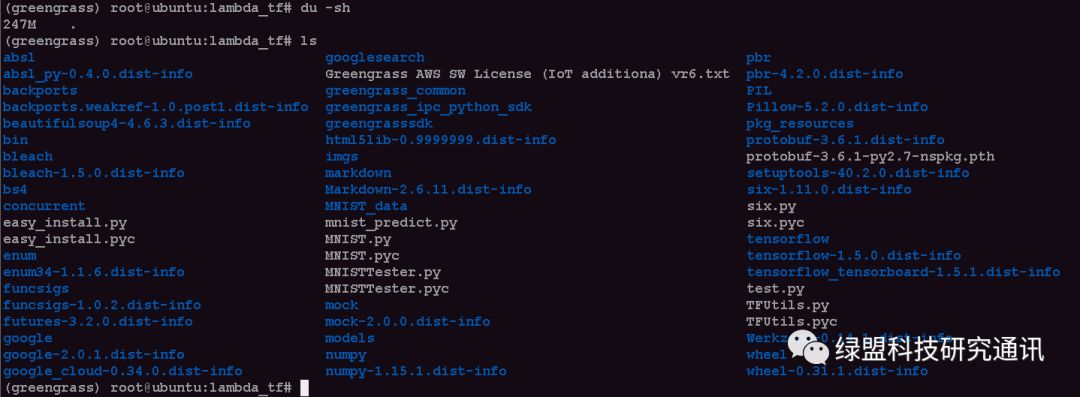
三、小节
以上主要介绍了基于AWS GG的机器学习模型开发与部署的实践。其实,无论是AWS GG还是微软的开源方案Azure IoT Edge,都是将各自云计算技术积累自然的拓展到边缘侧,通过统一的设计、开发、测试、部署、分析、管理、运维等环节,将IoT生态纳入到其各自的云计算架构下。这种自云向边缘的拓展是各大云计算厂商最直接的思路。
当前,著名开源组织Linux基金会和Eclipse基金会正在企划将Kubernetes引入边缘侧的计算场景中。华为刚刚开源的KubeEdge解决方案也正大力促成Kubernetes与边缘的融合,Kubernetes是否能像在云计算环境中一样在边缘侧大展拳脚,亦或者有其他方案一统江湖,为边缘计算提供统一、高效、安全的架构平台,让我们拭目以待。
内容编辑:安全大数据分析实验室 张润滋 责任编辑:肖晴
声明:本文来自绿盟科技研究通讯,版权归作者所有。文章内容仅代表作者独立观点,不代表士冗科技立场,转载目的在于传递更多信息。如有侵权,请联系 service@expshell.com。
 联系我们
联系我们 在线留言
在线留言 京公网安备11011202100645号
京公网安备11011202100645号