

眼看着GPT-2编故事的技能就要冲出天际,OpenAI直说着不敢开源完整模型。
对此,多数小伙伴选取了嘲讽的语调,激励团队早日开源:不如改名ClosedAI算了。

不过,来自斯坦福的Hugh Zhang,使出了完全不同的催更技巧。
对于“这么危险,不能开源”的说法,这位NLP研究人员不以为然。且理由丰满,条分缕析。
首先,他觉得危险的技术分两种:一种是破坏性的,一种是欺骗性的。应该分开讨论。
第一种,如果是子弹,不会因为你明白它的威力,就躲着你走。
第二种,如果是假消息,你只要知道PS,就不会相信普京骑熊。

网上观摩一下,普京骑什么的都有。
Hugh还认为,GPT-2远远谈不上危险,且开源比不开源更安全。他事无巨细的论述,为GPT-2引来了又一波热烈的讨论。
我们就来观察一下,Hugh为什么会这样讲:
越公开,越安全
1825年,相机诞生,大家都认为这是记录历史的一种公正的方式。
不过,人类很快就发现照片可以修改。

1988年,Photoshop发布,那时照片修改早已不算罕见,但大众还是天然地担心:人人都能轻易编辑图像的话,技术很可能被滥用。
如今30年过去,Photoshop变成了顺理成章的存在,社会也并没有因此受到什么严重的伤害。
为什么会这样?
因为,大家都知道Photoshop是什么。
诚然,近年来语音、文本和图像生成技术的高歌猛进,可能引发某种恐惧,让一部分人感觉一场大难就要降临了。
但更有可能的是,这些技术的发展也像Photoshop走过的路那样:社会大众会去学习,然后变得更有警惕性,更懂得怀疑。
那么,具体到GPT-2身上,又是怎样的情况?
这AI也没那么强
GPT-2是个文本生成模型,OpenAI就用它生成的几个故事,向公众说明这AI是个危险的存在。
最著名的作品可能就是发现独角兽的故事了。
人类给AI的两句开头长这样:
科学家们有个令人震惊的发现,在安第斯山脉一个偏远且没被开发过的山谷里,生活着一群独角兽。更加让人讶异的是,这些独角兽说着完美的英文。

AI续写的第一段长这样:
这些生物有着独特的角,科学家们就以此为它们命名,叫Ovid’s Unicorn。长着四只角的银白色生物,在这之前并不为科学界所知。

(故事全文,请点这里)
在独角兽的故事里,需要注意两件事:
第一,我们看到的故事,是AI写了10次之后,人类选出的最好的一次结果。
第二,人类给的开头,其实也是精挑细选的。
具体讲讲第二点,为什么选了“说英语的独角兽”这样的设定?
因为,奇怪的设定可以掩饰AI的瑕疵。如此设定之下,就算AI写的句子再不切实际,读者都会觉得很合适。
以及,就算不考虑这一点,独角兽的故事还是有不少缺陷:
首先,第一句的角 (Horn) 用的是单数,表示这种生物只有一只角,也吻合了独角兽 (Unicorn) 名字的含义;可第二句却改口说有四只角。

许多同学都发现了这个bug。
还有,人类写的开头提到,独角兽的发现是近期的新闻;而AI写的第三句话,却说这次大发现,是两个世纪以前的事。
你可能问,我们这样挑错,是不是太苛刻了?
并不,这其实反映出深度学习模型一个很重要的问题:
AI没有理解,它生成的文本到底是什么意思。

其实,要生成“乍一看没问题”的句子,并不是很难。
比如,后现代主义论文生成器 (Postmodernist Essay Generator) ,以及数学论文生成器 (Mathgen) ,都能写出语法没错的句子,但语义上可能不起任何作用。
反正,给不懂数学的人看,这两个公式都像天书:
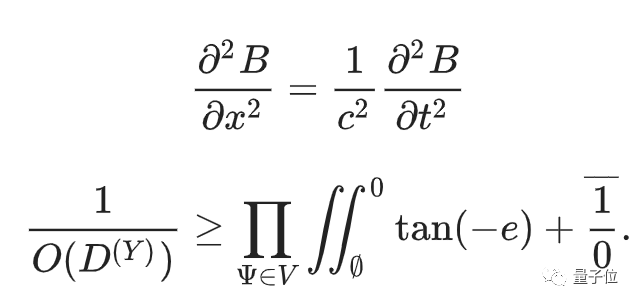
生成句子容易,上下文保持连贯就难了。
客观地说,GPT-2生成的作品,还是比之前所有的模型要好一大截;不过,和人类逻辑的一致性相比,它还差得很远。
GPT-2写出的那些故事,没有哪篇是能直接用来骗人的。

另外,也没有证据表明,15亿参数的GPT-2,比现在开源的缩小版更优秀。到目前为止,OpenAI官方并没有发布过GPT-2与任何现有模型的性能对比。所以,开源小模型,不开源完整模型,理由并不充分。
以及,OpenAI没有微调,所以也没办法在任何下游任务 (如概括、如翻译) 上,直接对比GPT-2和其他模型的表现。
为何应该开源完整版?
有些人会认为,没必要开源完整版,现在这个1.17亿参数的缩小版就够了。其实这是有问题的。
AI研究的爆发,一部分归功于开源:研究人员直接在现有模型基础上迭代,省去了重造轮子的时间。

作为现今最有影响力的AI研究机构之一,OpenAI拥有强大的开源传统,这也鼓励了其他研究团队开源自己的成果。
如果OpenAI的新政策反其道而行,许多其他研究人员也可能效仿。AI领域的开源文化,可能就会受到冲击,每个人都会有损失。
另外,开源也有利于把技术发展的消息,向领域之外的公众进行传播。
举个近期的例子。
英伟达开源了StyleGAN之后,用这个算法生成假脸的网站thispersondoesnotexist.com,速速成为了大众讨论的主角:

刷新一次,生成一张脸。要让普通人感受到AI技术的发展,可能没有比这更简单的体验了。
再举个例子。
世界上第一幅参加艺术品拍卖的AI画作,也是用开源算法生成的。

这幅名叫Edmond de Belamy的作品,在佳士得拍出约合300万人民币的价格,还引起了不小的争论。
就像前文说的,普通人越了解技术发展的程度,也就越有能力辨别AI生成物,越能避免被虚假消息淹没的灾难。
而如果OpenAI真的认为,这是一项非常危险的欺骗性技术,可以在发布论文之后,多等一段时日再开源。
这样,公众便有时间去了解它的生成效果有多逼真,做好准备。
One More Thing
不过,在Hugh的催更文发酵的同时,OpenAI也宣布了一项斩钉截铁的举措:
为了部落AI技术的安全,我们需要社会科学领域的贤才,现在已经开始招人啦!

这是一则认真的招聘启事,申请入口已开放,还附以OpenAI的一篇论文和一篇博客,以示决心。
核心观点就是:AI安全,需要社会科学家。
如果方针是安全为上,OpenAI谨慎的开源操作,大概也不会止于这一次了。
Hugh Zhang催更原文:
https://thegradient.pub/openai-please-open-source-your-language-model/
社会科学家投简历请至:
https://jobs.lever.co/openai/dd3f7709-6651-4399-b2b4-4f27abcbd296
探讨AI安全的论文:
https://distill.pub/2019/safety-needs-social-scientists/
GPT-2编的更多故事:
https://blog.openai.com/better-language-models/#sample8
声明:本文来自量子位,版权归作者所有。文章内容仅代表作者独立观点,不代表士冗科技立场,转载目的在于传递更多信息。如有侵权,请联系 service@expshell.com。
 联系我们
联系我们 在线留言
在线留言 京公网安备11011202100645号
京公网安备11011202100645号