
军事智能化的发展重点之一是人工智能的军事应用。人工智能的高级阶段是认知智能,认知智能的基础是知识。加强以知识为中心的情报智能研究,利用自然语言处理、计算机视觉、语音识别、机器学习、图数据等技术,研究知识的获取、存储、推理计算和应用,实现典型情报分析场景的感知智能和认知智能。
1、从一个假想案例讲起
我国边境线长达2.2万公里,与14个国家接壤。在边境线上,有时会因为他国内部的战乱,发生流弹入境、难民涌入等事件。然而,“边境无小事”,任何边境情况都会牵动国家利益。维护国家边境安全,一直是陆军边防部队和情报部门关注的重点。那么,该如何有效应对难民涌入、流弹入境等边境安全事件呢?首先需要我们利用情报智能技术,实现对边境地区安全事件的感知和预测。
2017年3月5日,我陆军情报部门在常态值班时监测到XX政府军兵力调动、主战装备移防、民地武兵力调动。3月6日上午,获取情报“XXX空军基地起飞2架战机,配合地面部队,对XXX发起打击。”1小时之后,在互联网社交网络上,多人在Facebook、Twitter、微博上发出关于这次行动的消息,如“边境炮火连天,飞机呜呜地飞,又开打啦!”“可怜的XX人民……”。
有了这三件事之后,我陆军基本上判断得出一个结论:确实出事了。在启动应急处置预案之前,首要的工作是确定两个问题:一是XX政府军可能对什么位置的敌方武装据点发起多大规模的打击?二是分析难民涌入、流弹入境事件发生的可能性及位置分布。
回答第一个问题需要利用精细的情报分析手段。我陆军通过多时相航天遥感影像和地理空间分析,针对动向目标位置识别目标,获取冲突双方的兵力态势及特定目标的图像特征,得到冲突地点应该是XXXX区首府XX。
回答第二个问题需要一套系统(如图1所示)在后面做支撑。情报部门通过历史案例库训练,已经建立了难民涌入、流弹入境等事件发生的早期关联信号,构建了难民群体的行为分析、追踪模型与规则,即每当XX政府军的兵力有变动,比如说:起飞多少架飞机、动用多少兵力,总会意味着一个什么烈度的战争形式。每当有这样一个烈度的军事行动时,当地老百姓是一个什么行动规律。经过系统解算,预测难民涌入事件发生的概率为95%,时间为3月6日晚间,地点在边境XX口岸10公里范围内,规模约10000人。
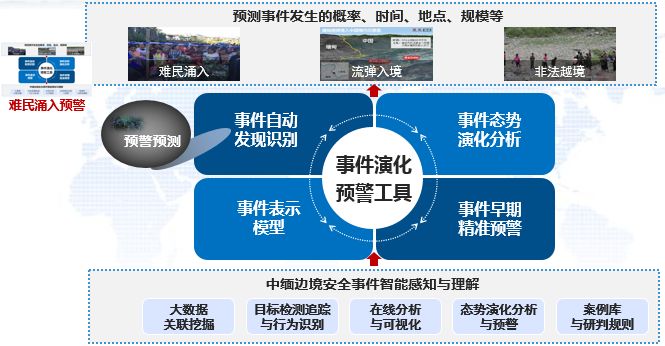
图1 情报分析系统
武装冲突发生后,我方需要以军警民联合的方式,紧急开展边民疏散和难民引导。为此,该系统可辅助生成处置预案。针对可能的流弹入境,炮瞄雷达开机以探测炮击情况及方向,无人机升空巡防以监控流弹入境情况及分布。针对可能的难民涌入,边防部队加强巡逻疏导,边境口岸通过视频开展通关目标识别、人员流动及数据统计,地方应急保障部门按需定量接收难民。
从这个案例的处理过程,我们可以总结出3个特点:一是数据融合。该案例采用“天空地网一体,军警民联合”的模式开展边境安全事件的分析、预警与辅助决策,涵盖了军警民边境业务数据,包括军事情报、口岸通道、航天影像、边境监控视频、无人机、网络开源数据等,情报人员最终的结论建立在跨域融合的情报基础之上。二是跨域解算。结合多语种、多文化背景和边境地区安全事件特点进行跨域解算。三是预警预测模型的建立。大数据时代下,历史数据的积累和利用也很重要,本案例的预警预测模型,就是基于历史案例库进行标注、训练与预警信号抽取的。这些问题的解决方案之一,就是我们提出的以知识为中心的情报智能。
2、知识
军事智能化的关键支撑之一是人工智能,对形成战斗力更重要的是认知智能,而不仅仅是现在更为成熟的感知智能,人工智能还有很大的发展空间。
认知智能的基础是知识,知识是我们所研究的问题域中的概念与实体,以及这些概念与实体的属性、相互关系、约束规则、过程步骤等的集合。知识的本质是反映我们所关注的客观世界的时空因果,可以把它物化成一个知识库,其中包括本体、知识图谱、规则、过程性知识等。人类知识分两大类:一类是陈述性知识,另一类是过程性知识。知识图谱目前主要面向的是陈述性知识。
可以说,知识是我们跟数据之间的一个桥梁,是我们赖以理解数据和解释现象的基础;知识是机器学习能力的倍增器,它可以降低机器学习的样本依赖,增强机器学习与先验知识融合;知识是人工智能可解释的赋能器;由于数据红利降低、深度学习天花板、感知智能红海,知识引导将成为任务求解的基本方式;知识是比数据更重要的资产,知识是人类进步的阶梯,知识图谱是人工智能进步的阶梯。
3、以知识为中心的情报智能
情报智能是指在云计算和大数据环境下,利用自然语言处理、计算机视觉、语音识别、机器学习、图数据等技术,研究知识的获取、存储、推理计算和应用,实现典型情报分析场景的感知智能和认知智能。
以知识为中心的情报智能研究分三个方面。一是知识获取。研究如何从文本、图像、社交网络、数据库中把知识抽取出来,如何跨媒体多模态获取知识。二是知识构建,其中包括知识存储与知识计算。一方面研究如何大规模地存储、高性能地查询、动态地更新已经获取的知识,另一方面分析挖掘知识潜在的关联关系,产生隐性知识。三是知识服务。主要体现在:(1)智慧搜索,由问题通过推理得到答案;(2)阅读理解与问答;(3)场景服务,建立典型情报分析场模型;(4)百科条目服务,为掌握情报“基因”提供支持。
以知识为中心的情报智能,其基本机理和理念就是“理解、关联、洞察、预测”:
一是理解现象。抽取情报的自然属性和社会属性,对情报的主体、场景、行为、情感建模。涉及的核心技术有:自然语言理解,语义标注,用户行为分析,深度学习,概率模型,知识图谱,社区发现,群体行为建模,信息传播理论等。
二是关联线索。根据自然属性和社会属性之间的语义关系,链接相关情报。涉及的核心技术有:相似性检索,相关性计算与搜索,图(网络)模型、多变元网络、链路预测,概率化建模,字典学习方法,马尔科夫随机场等。
三是洞察本质。揭示目标或事件的完整面貌、来龙去脉、前因后果、特点规律。涉及的核心技术有:目标画像,事件拼图,因果推理,超图模型,迁移学习,复杂网络分析,流形学习,可视化分析等。
四是预测变化。预测事件发展趋势、目标后续行动。涉及的核心技术有:回归分析,模型推演,贝叶斯预测,异常模式检测等。
4、以知识为中心的智能情报系统技术框架
以知识为中心的智能情报系统的技术框架由5层组成,即数据层、感知层、知识层、认知层和应用层(如图2所示)。
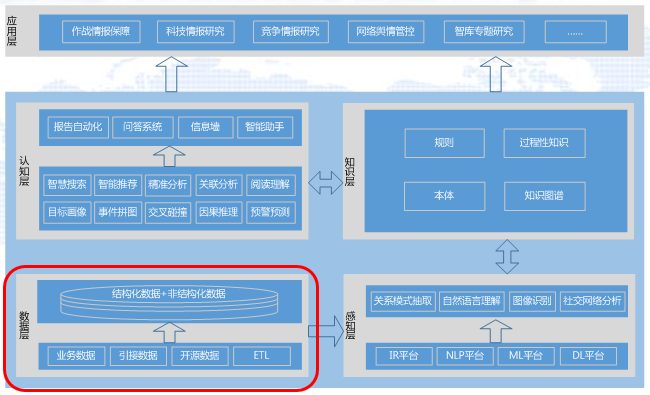
图2 以知识为中心的智能情报系统的技术框架
(一)第一层:数据层
数据层主要是构建一个大数据池,其中包括3个进水管、1个滤水器和1个水池子(如图3所示)。内部情报数据、引接过来的兄弟单位的数据、网络开源数据进行清洗后,分别从这3个进水管流入大数据池。
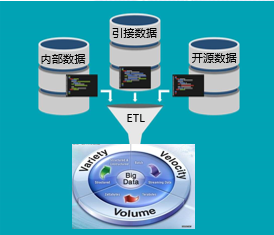
图3 大数据池
大数据池的设计要体现敏捷、在线、跨域的特征。一是采取敏捷大数据架构,跨域大数据无缝融合的关键在于数据模型是基于动态本体的,是灵活、动态、全尺度、无边界的,而且要能反映人、事、物和环境的时空因果关联关系和推理过程;二是通过自动采集、自动抽取、自动生成、自动同步联动等技术保持数据始终在线,“为有源头活水来”;三是通过语义理解和图式化技术,将分散化、碎片化的跨域数据构成一个完整的逻辑体系。我们的经验体会是,从成本和效果看,在统上下功夫不如在融上下功夫。目前,大数据池的逻辑模型和物理模型设计均采用的是成熟产品,但最麻烦的是,没有好用的做这个水池子概念模型的设计工具。
在构建大数据池方面,需要重点关注以下五个关键问题(如图4所示)。
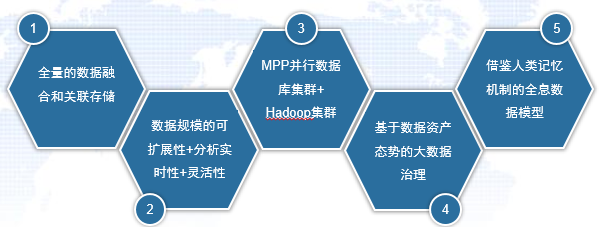
图4 数据层的关键问题
(1)全量的数据融合和关联存储。通过本体,抽象出各类数据资源的关系,进行映射存储和关联索引;这时,就要发挥知识库的作用,知识图谱不仅为智能分析做支撑,同时也应该可以作为大数据池里数据的索引。
(2)敏捷的大数据架构。重在数据规模的可扩展性,兼顾分析实时性和灵活性。情报系统的大数据体系和知识库是无边界的,是随时可拓展的。比如情报、审计、公安、纪检政法等大数据,今天可以引接进来民航数据,明天可以引接进来电信数据,后天还可能引接进来微信数据,也就是说,会不断动态地引接数据进来,不可能说我已经建成了情报大数据体系、已经建成了情报知识库,我们不应该也无法试图去预先建立一个完整的数据和知识体系,然后再在其之上进行大数据分析和知识计算,而应着力建立起一个敏捷、弹性的架构。
(3)大数据的存储和管理。我们面对的是结构化和非结构化数据混合的大数据,因此,需采用MPP并行数据库集群与Hadoop集群的混合集群来实现对百PB量级、EB量级数据的存储和管理。一方面,用MPP来管理、计算高质量的结构化数据,提供强大的SQL和OLTP型服务(比如,作为一个MPP,在非常大的数据集合上运行包含复杂连接操作的聚集查询时,在MySQL上需要6个小时,但是在AmazonRedshift上,只需要几秒钟,而且不需要任何修改);另一方面,用Hadoop实现对半结构化和非结构化数据的处理,以支持诸如内容检索、深度挖掘与综合分析等新型应用。这类混合模式是大数据存储和管理的“标配”。
(4)基于知识图谱和数据态势的大数据治理。数据管理成本大概每年每TB一万块钱,大数据治理非常重要,这方面不多说了。强调一点,从情报系统的角度看,很需要利用可视化的手段展现情报数据资产态势图、情报数据体系全局视图、情报数据血缘关系、情报产品生产消费链条等。
(5)借鉴人类记忆机制的全息数据模型。当我们想要提取某段记忆时,往往只需要只言片语就行了。也就是说,记忆似乎是以一种全息的形式存储的,任何片段都包含了全部。从全息理论的借鉴意义上看,所谓全息,就是指从任何一个点入口,都能得到整个世界,小中见大,见微知著,管中窥豹,一滴水里观沧海,一粒沙里看世界,一滴水里藏乾坤。要研究一下全息理论,了解为什么广泛连接就能够见微知著。进一步说,我们能否发明一个全息数据模型,使其通过任何片段入手都能获得全部所需信息呢?这个数据模型是否也该有类似轴突、树突的机制设计?是否也该具有一种类似大脑皮层和深度学习的抽象层次?是否会是一种类似金字塔+超图的模型?
(二)第二层:感知层
感知层主要负责语义理解和知识获取。感知层分为上下两层。下面是平台层,包括信息资源(IR)平台、自然语言处理(NLP)平台、机器学习(ML)平台、深度学习(DL)平台等;上面是知识抽取层,负责从关系数据库、自然语言、图像、社交网络等抽取知识。知识抽取层的基本工作思路是,从图文声像和关系数据库中分别抽取实体、关系、属性。现在,实体抽取相对比较成熟,关系抽取的精度还不够高,尤其是形成因果关系比较难。抽取实体、关系、属性的目的,是把实体、关系、属性按照目标、事件、时空、因果进行组织,分类进行表达(如图5所示)。
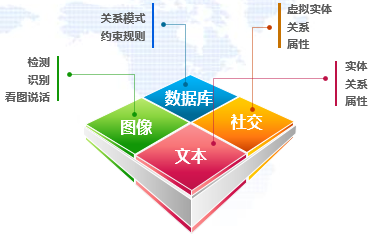
图5 各类数据的抽取要素
在这一层,有以下六个难点问题(如图6所示)。
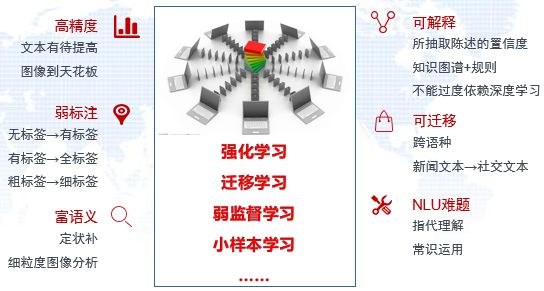
图6 感知层的关键问题
(1)高精度。按实际经验,用一些经典的机器学习和自然语言处理方法可以把精度做到85%,但是,需要用更深、更强的算法配合更大的数据量,才能把精度提高到95%。若要将精度做到99%,就需要在算法方面有所突破,还要充分引入规则、常识等先验知识。比如做阅读理解,首先,把每一篇文章中的每一个词汇,翻译成词汇向量;然后,从每一个语句的一连串词汇向量中提炼出语句向量;再然后,把每一个段落的一连串语句向量提炼出段落向量;最后,从段落向量中提炼出整个文章的文章向量。这样,每篇文章就构成了一个树状的向量集合,根节点是整个文章中心思想的文章向量,上层中间节点是段落向量,下层中间节点是语句向量,每个叶节点是词汇向量。从语言研究的角度看,这里所谓的“提炼”,有什么规则?还是说没有什么规则,只能靠大量标记样本进行学习训练。
(2)弱标注。情报大数据是典型的弱标注样本。如何采用无监督学习解决无标签问题,如何采用半监督学习解决部分样本有标签的问题(就像医疗数据那样),如何采用弱监督学习在弱标签指导下学习强标签。
(3)富语义。程度副词、时间状语、条件状语等定状补成分可以用来确定所抽取陈述的概率化和时态化,如因果关系抽取,按照句型模式抽取出因果句子,再切分出因果因子。情报领域的知识图谱很多知识是动态的、不确定的、有时效性的,不像百科。另外,细密度的图像分析也很重要,比如说XX自拍APP,很多女孩用它自拍并把照片放到其服务器上,如果这几天女孩熬夜看世界杯,因休息不好,脸上长了很多的痘痘,这时,这个APP就可以利用这些数据,对她精准营销化妆品。情报领域也有类似的需求,不只是停留在目标识别上。
(4)可解释。所抽取陈述的置信度,导致知识图谱的概率化;不能过度依赖深度学习,知识库要反哺,尤其是要充分发挥知识库中规则的作用。
(5)可迁移。借用大量已有的英文/中文标签数据并将其应用在任何一种语言中,如谷歌的韩英+英日=韩日;大多自然语言处理算法是在新闻类数据上训练并评价的,如何应对社交媒体数据?
(6)自然语言理解难题。自然语言理解最难之处在于指代的理解和常识的运用。
(三)第三层:知识层
本层主要对本体、知识图谱、规则、过程性知识等进行存储与管理。本体是领域知识中的概念及其相互关系。知识图谱是本体概念体系下的领域实体和事实,利用知识图谱可以进行实体对齐、隐性知识挖掘等。规则包括知识推理规则和规则性知识。过程性知识是有关“怎么办”的知识,大多可以从条令条例、规章制度、操作手册等文档中抽取。一般来讲,知识库中的数据有三个来源,即百科、结构化数据库和非结构化的图文声像数据的抽取。
在知识层,现在有以下一些关键问题还没有解决好(如图7所示)。下面的分析只围绕知识图谱展开。

图7 知识层的关键问题
(1)知识融合
涉及实体融合和关系融合。在情报分析中常见的难点包括:网名的识别和对齐链接,短文本中的实体识别与链接,跨语言文化等。
(2)知识表示
知识图谱一般用关系数据库和nosql数据库,当节点上亿或者关联查询六步以上一般就要用到图数据库了。但图数据库目前还不够成熟,对在线查询等在线操作性能不够高。
概率化:知识图谱里面的内容有两种理解:一是被验证正确的知识和客观事实;二是从数据陈述中提取出的语义内容的组织与表达,不一定是正确的知识。严格地说第二种并不是严格意义上的“知识”图谱,只是一份数据的图示化语义陈述与表示,需要不断验证、增补、概率化、完善成知识图谱。
(3)知识推理
也叫知识补全、链路预测。知识补全的主要任务是预测事实三元组中缺失的实体或者关系,其中的关键问题是在于如何更好地表示知识库中实体关系特征。此外,在本体推理与规则推理中,如何在大数据量下进行快速推理,以及对于增量知识和规则的快速加载。这些既需要机器学习算法,也需要图论相关算法的突破。
(4)知识更新
就是知识库中的知识与现实世界同步。天天全网爬肯定行不通,况且也不是库中的每个实体都需要更新,例如,“军舰”这个基本概念的内涵外延就很少会发生变化。但是像一些时空类、职务类的属性就很有可能发生改变,还有新词、热词等。那么,如何检测知识的变化?如何预测更新的频率?如何实现相关实体的联动同步?另外,在情报领域,出现与知识图谱中已有模式相矛盾的新模式,有时可能意味着我们探测到了一种异常并可加以预警。
(四)第四层:认知层
认知层是典型的场景驱动,也分为两层。底层是任何一个搞情报应用的团队都值得着力的地方,或者说,该层体现团队核心竞争力。该层有情报常用的10个场景,即智慧搜索、智能推荐、精准分析、关联分析、阅读理解、目标画像、事件拼图、交叉碰撞、因果推理、预警预测。用户并不直接感受到这10个场景,他们可以通过四个入口来使用这10个场景,即上层的报告自动化、问答系统、信息墙和智能助手。其中:(1)智能助手是在后台完成的,前端界面上看不到显式的数据知识服务类功能菜单,系统能够自动感知当前的操作场景,后台主动推荐或随叫随到地提供知识助手、数据助手和分析助手服务。(2)问答机器人(虚拟参谋)是进行十亿级知识库访问的有效手段。与聊天机器人不同,问答机器人追求的目标是用尽量少的轮次就能给出令人满意的答案。
(五)第五层:应用层
应用层主要强调的是深耕垂直细分领域,比如说作战情报保障、科技情报研究、竞争情报研究、网络舆情管控和智库专题研究。需要注意的是,大数据+人工智能类的系统与传统的信息系统建设项目不同,是受场景驱动的,尤其是人工智能赋能的,需要不断试错调参,要注意前沿技术运用与进度控制的协调。
(六)着力点
在数据层,主要靠工程化的解决方案,比全量、质量和关联度。在感知层,其平台层靠主流产品集成,比性能和稳定;其知识抽取层靠算法,比精度、粒度和样本依赖。在知识层,靠融合积累,比自动化和动态性。在认知层,靠领域业务模型,比分析的维度、深度、广度、可视度。在应用层,靠场景,比创意。
图文 | 肖卫东,葛斌 (国防科技大学信息系统工程重点实验室),发表于《中国指挥与控制学会通讯》2019年第3期
声明:本文来自军事高科技在线,版权归作者所有。文章内容仅代表作者独立观点,不代表士冗科技立场,转载目的在于传递更多信息。如有侵权,请联系 service@expshell.com。
 联系我们
联系我们 在线留言
在线留言 京公网安备11011202100645号
京公网安备11011202100645号