
文|宙斯盾流量安全分析团队
晨晨、彦修
背景
企业数据包含着用户个人信息、隐私信息、商业敏感数据等,一旦泄漏,会给企业带来巨大的经济损失,甚至承担相关法律责任和巨额罚款。因此,如何保障企业存储的各类敏感数据的安全,成为企业信息安全工作的重中之重。
笔者所在的团队是基于流量来进行安全分析建设工作的,针对敏感信息的防护场景主要分为两个,第一个是针对疑似外部批量拖取数据的监控,包括利用常见的越权漏洞、注入漏洞等;第二部分则是针对业务数据脱敏情况监控,主要是发现业务的疑似未脱敏风险并及时推进处理。
传统的敏感信息检测方式基本采用关键字或正则去匹配响应中的敏感信息,如未脱敏手机号,这些主要依赖安全运营人员的经验,误报率和漏报率都比较多。此外,项目运营初期,精力和资源也较为有限,如何优先跟进处理中高风险事件也是团队比较关注的问题。基于以上原因,我们利用机器学习实现了一种快速且高度自动化的敏感数据治理方案,该方案可以实现对敏感信息的检测、分类、分级运营等目标。
传统 VS AI
现有的敏感信息检测依赖经验知识,通过经验指定敏感关键字或正则对响应内容进行匹配,从而筛选出敏感信息,规则不全将导致漏报。同时,根据命中的关键字不同,划分至不同的敏感信息类型,这种方式简单粗暴,准确分类往往需要结合上下文,对于同时命中多类关键字的,很难准确合理划分。威胁分级则主要通过维护一张敏感信息类型与级别的对应表,不同类型处于不同级别,规则灵活性差。机器学习方案可以有效弥补上述不足,如图1:
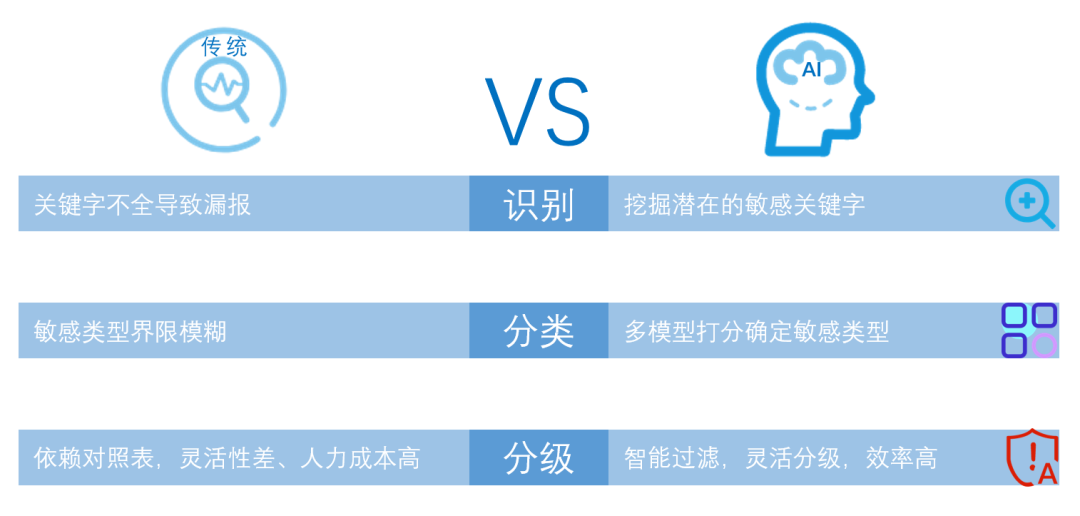
图1 传统方案与AI方案对比
系统概览
一、敏感数据治理系统架构
敏感信息检测系统的设计采用机器学习为主导,人工干预为辅助的处理机制,并随着算法的不断优化与数据模型的不断完善,逐步降低人工干预的比例,整体架构如图2。敏感信息检测系统分为流量识别、数据处理、模型层处理和运营四个阶段:
-
流量识别:对流量进行分析,去除无用页面,同时构建模型监控数据外泄。
-
数据处理:对响应内容进行去脏、分词、过滤等预处理步骤。
-
模型层处理:核心模块,基于机器学习算法对响应中的敏感信息进行识别、分类并分级。
-
运营:基于模型层分级结果,针对高风险场景优先推动整改;跟踪模型表现,根据运营实际情况,不断调优模型。
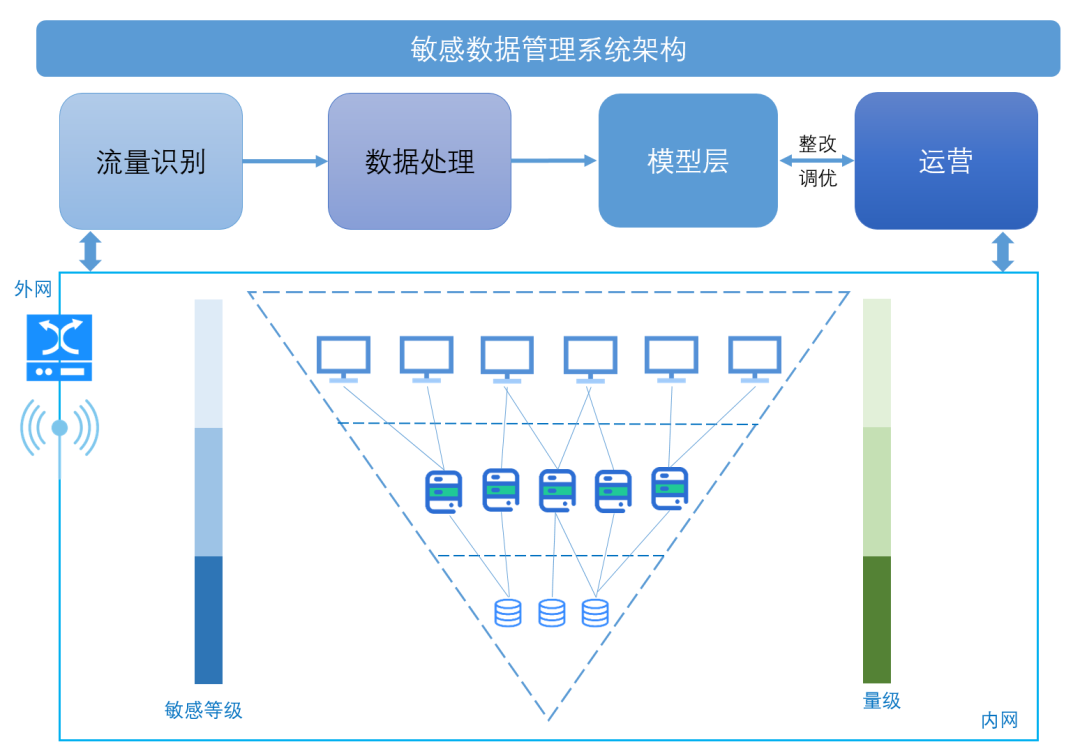
图2 敏感数据检测系统架构
二、模型层
模型层是整个敏感数据管理系统核心,完成从敏感信息的识别,到分类,到威胁分级的整个流程,如图3。该方案流程如下:
Step1. 敏感信息识别
通过TF-IDF算法挖掘潜在的敏感关键字,扩充至规则库,弥补关键字不全造成的漏报。
Step2. 敏感信息分类
通过建立不同类别的敏感信息模型,每个模型输出一个概率值,用于指示待检测信息属于各类的可能性,选择最高的值代表的类型作为敏感信息类型。
Step3. 威胁分级
通过word2vec模型训练词向量,并作为特征输入k-means聚类算法中进行过滤,筛选出疑似有风险的部分输入威胁分级模型,根据不同级别分级运营。
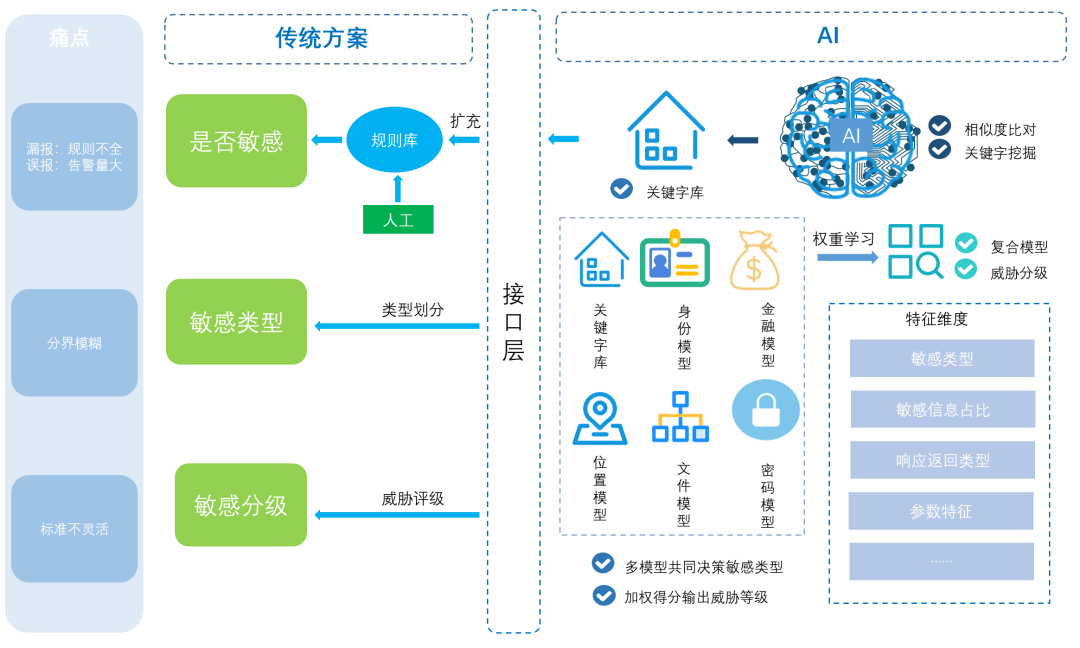
图3 基于机器学习的敏感信息泄露检测-分类-分级方案架构图
2.1 敏感信息识别
敏感字段包括业务配置信息、手机号码、系统信息、账户密码等等。传统方案对敏感字段的识别主要通过规则库进行匹配,而规则库的生成主要通过关键字、正则表达式和算法。前2种方式十分依赖经验的积累,如若关键字与正则列表不全,将造成漏报。于是,我们考虑通过算法挖掘潜在关键字,用于扩充规则库。这里我们选择TF-IDF,基于TF-IDF的关键字提取流程如图3。
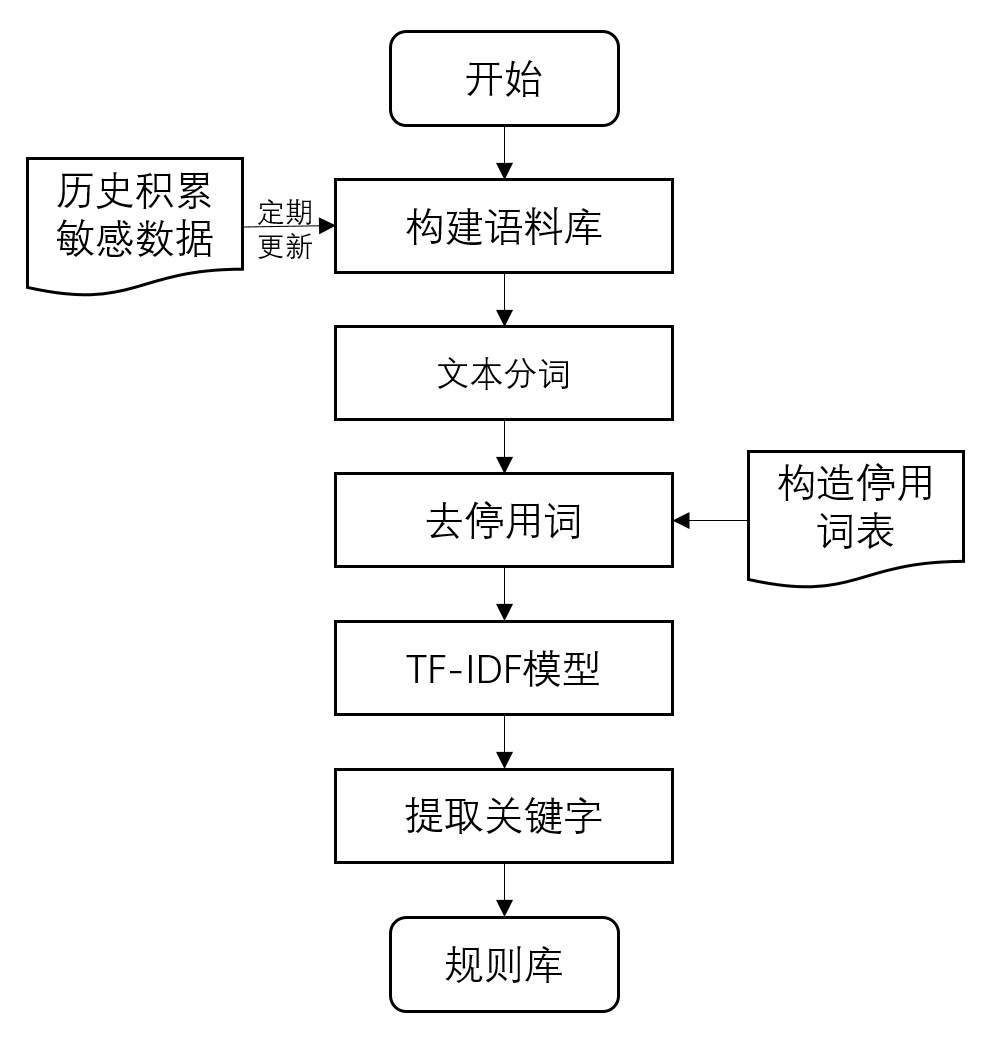
图4 关键字提取流程
2.2 敏感信息分类
传统的基于命中关键字判断敏感类型的方式,往往不够准确,需要结合上下文语义进行综合判断。机器学习模型可以模拟人脑判断类别的复杂方式,包括对内容进行语义学习,上下文判断与关键字抽取等。通过建立不同类别的敏感信息模型,如身份模型、金融模型、位置模型等,待分类敏感信息同时通过每个模型输出一个概率值,用于指示待检测信息属于各类的可能性。最后选择最高的值代表的类型作为敏感信息类型,如图5。
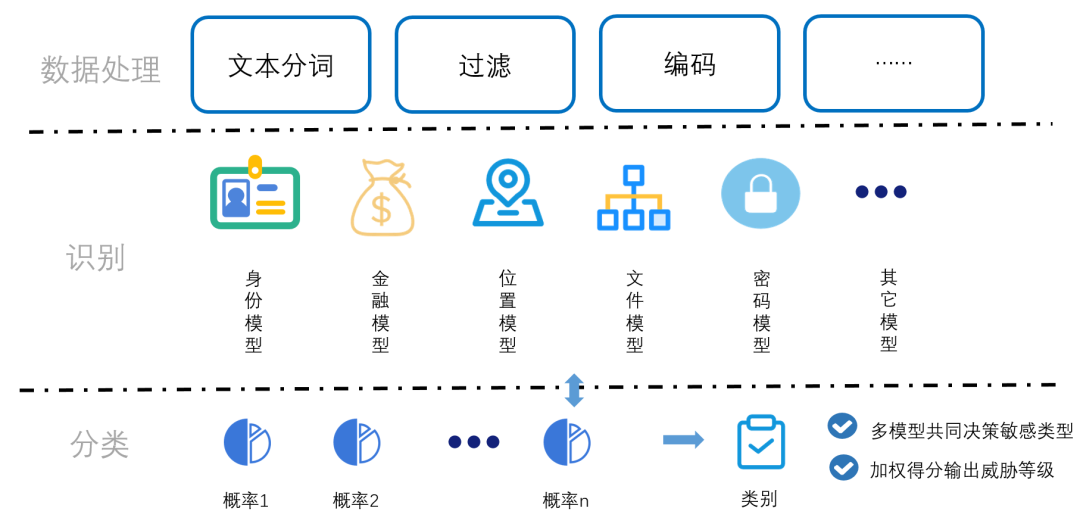
图5 敏感信息分类流程
2.3 敏感信息分级
威胁分级模块基于敏感信息分类模块的分类结果,对敏感信息进行威胁评级,这里包括2个子模型:k-means过滤模型、威胁评分模型,流程如图6。
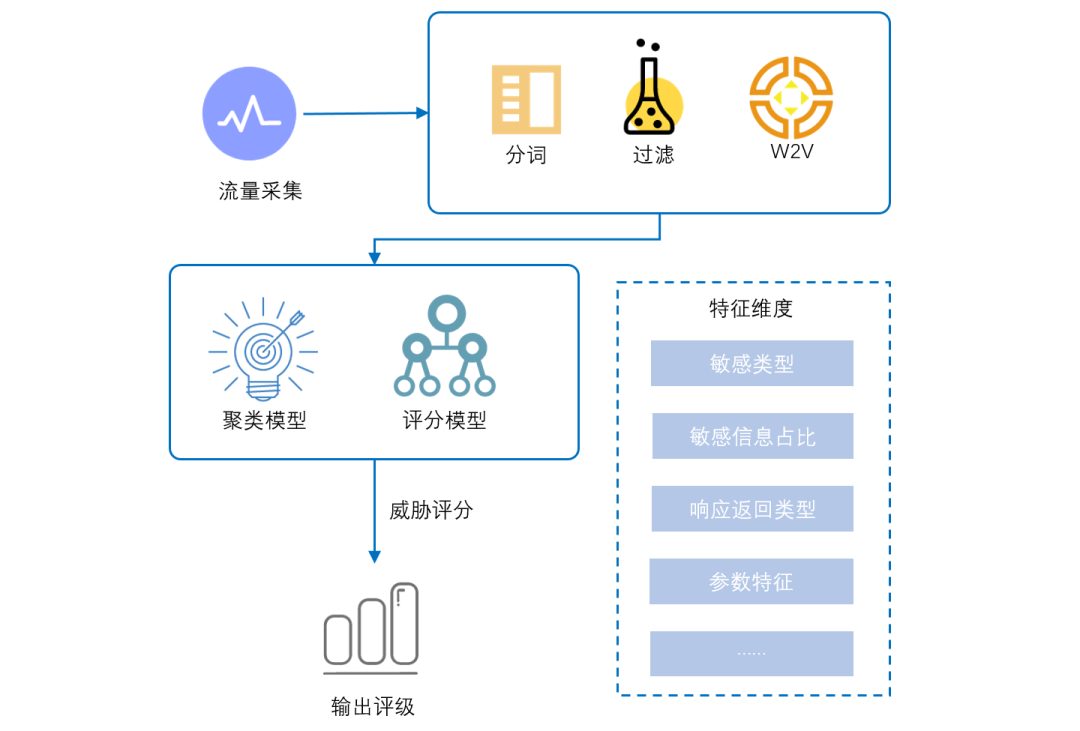
图6 威胁分级架构图
step 1
对待分级内容进行分词、过滤等预处理步骤,通过word2vec模型获取词向量,并输入k-means聚类模型中。
step 2
聚类模型自动学习信息间的相似度,并输出待分级内容所处的簇,我们默认规模最小的一个簇最可能具有最高威胁等级。经过前面步骤,可过滤掉大部分误报或低风险内容,并筛选出疑似的高危信息。
step 3
疑似的高危信息输入威胁评分模型进一步分级,选出真正高危的信息进行整改。我们选择命中敏感信息种类、批量拖取频率等20个维度作为特征,模型对这些特征赋予不同权重,对待分级文本进行评分。
Step 4
依据分数对威胁程度进行评级,输出高危、中危、低危的标签。
写在最后
敏感信息泄露将对企业带来巨大的经济损失,甚至是法律责任,所以企业敏感数据保护至关重要。机器学习方案可以作为传统方案的补充与完善,为企业敏感信息保护带来新思路。
当然,目前机器学习方案还有很多可以优化的空间,比如针对图片类、视频类等相关场景。在这里我们也做了一些尝试,比如可以对图片先进行OCR识别,获得的文本则可以进入后续流程,限于篇幅原因,就不再过多说明。另外,不可忽视的是,在提升检测能力的同时,也需要加强信息泄露的防范。这才是最根本的解决之道,不能舍本逐末。
基于机器学习的敏感信息泄露检测-分类-分级治理方案是我们在流量安全分析领域一个小小的尝试,未来我们也将持续探索更复杂的场景与更丰富的解决方案,不断拓展,为流量安全发掘新思路,也希望为业界带来一些新想法。
敬请大家关注我们后续的流量系列相关文章。最后我们也希望在探索这些方案的同时能够与大家一起讨论分享,如果你有更好的想法或者对流量安全相关的工作感兴趣,欢迎与我们联系。团队长期招人,简历请投至 security@tencent.com
声明:本文来自腾讯安全应急响应中心,版权归作者所有。文章内容仅代表作者独立观点,不代表士冗科技立场,转载目的在于传递更多信息。如有侵权,请联系 service@expshell.com。
 联系我们
联系我们 在线留言
在线留言 京公网安备11011202100645号
京公网安备11011202100645号