
引言
在软件侵权案件中,面临着涉案数据规模不断扩大,侵权手段越来越复杂的状况,近20年随着文本挖掘和深度学习技术的发展,代码相似性检测技术取得了很多进展,但是每类检测技术的检测效果有限。本文提出在软件相似性司法鉴定中根据不同的场景采用多种代码相似性检测技术相结合的方式以获得更为准确的检测结果,并分享两个不同场景软件相似性鉴定案例中的鉴定方案。
司法鉴定领域软件相似性鉴定的现状与问题
涉及软件侵权案件审理中,一般会指定第三方鉴定机构对涉案软件进行相似性鉴定。在传统的软件相似性鉴定中,鉴定人一般使用Beyond Compare、Araxis Merge 、UltraCompare等比对工具,对涉案双方的代码等进行逐一比对。这类比对工具有较大的局限性,对于文件间文本内容存在顺序或布局差异和文件目录结构和文件名存在差异的情况自动化支持程度不高,因此仅适用于比对双方的目录结构和文件名相近似,代码布局和顺序没有较大调整的情况。然而随着技术的发展,软件侵权手段越来越多样和复杂,涉及的电子数据检材越来越多,给鉴定带来了一定的难度和挑战,传统的鉴定工具和方法已经不能满足一些案件的鉴定需求。
代码相似性检测技术简介
代码相似性检测技术框架分为4个部分:预处理、中间代码转换、比较单元生成和匹配算法。其中核心部分是中间代码转换和匹配算法。中间代码转换是利用不同的检测方法对代码做中间表现形式的转换,将其转换成字符、Token序列、抽象语法树、程序依赖图、程序属性等,然后在转换后的新结构上,使用不同的匹配算法实现相似性检测,匹配算法有字符匹配、指纹匹配算法、子树匹配、子图匹配、直接比较、欧式距离、度量值比较等等。基于字符和Token序列的检测侧重代码的表达检测,其他检测方法则更注重于挖掘代码的结构特征。
基于上述的检测技术和方法,出现了很多开源或者收费的代码相似性检测工具,比如NICAD、SIMIAN、CHECODE、TPM、BINDIFF、IDACOMPARE、NBD等,其中比较常用的NiCad工具一般用于源代码检测中,可以处理C,Java,C#,Python,PHP等语言,可以以function和block两种粒度进行检测。BinDiff一般用于二进制代码检测中,是基于图形和指纹理论开发的IDA Pro插件,其函数匹配主要是基于从CFG(函数控制流图)中得到的NEC值,即基本块数、边数、调用数,跨架构寻找匹配签名的函数。
软件相似性鉴定中代码相似性检测技术的应用
4.1思路
一般而言,软件相似性鉴定中代码相似情形可以分为以下几类
A:内容完全相同。
B:代码文件中的函数位置或者代码布局发生了变化,但是代码实质内容没有变化。
C:除了空格、注释之外的代码完全相同。
D:对函数名、变量名、常量名、类型名做了对应性替换,其他代码完全相同。
E:代码中存在增加、修改、删除,或者少量语句顺序改变等情形,但仍然存在较多的相同代码内容。
F:其他不合理的相似,例如存在软件署名、开发者的姓名、单位、废程序段、独特的代码序列等相同。
G:代码逻辑功能相同,但是实现方式不同,代码内容存在差异。
但是目前尚未出现一种检测方法或工具能够检测出上述所有的相似情形,经过实践证明,使用相同的代码样本,使用不同的检测方法和工具得到的检测结果是不相同的,甚至有些工具和方法存在误差。在司法鉴定中,涉及源代码的鉴定,一般需要检测出A-F六种情形,涉及二进制目标代码的鉴定,则需要检测出A-G七种情形,如果涉及到算法则需要检测出G的情形。因此,在鉴定过程中,需要结合具体的案情背景、检测目标和检材样本内容,使用文本、特征向量、树、结构等多种方法相结合的检测模型,以得到更加准确、更加符合鉴定需求的结果。
4.2源代码相似性鉴定的实现方案
本案例涉及某侵权案件中的源代码相似性鉴定。权利方提供了涉案4款软件中不为公众所知悉的上千个源代码文件,被举报方的检材涉及到了被保全的多块电脑硬盘。本案例的特点是,检材多源代码量大,涉及小集合与大集合内容交叉比对。本案例的鉴定方案如下图1所示。
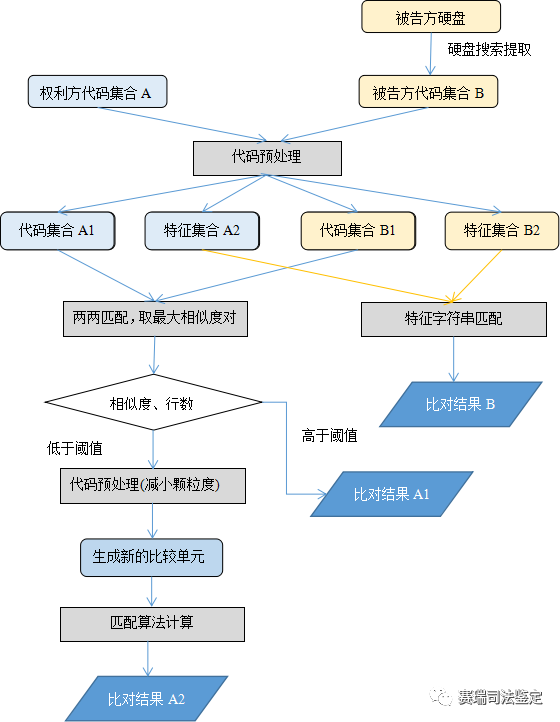
图1源代码相似性比对鉴定方案
在源代码的相似性鉴定中,侧重于检测源代码文本的相似性,因此一般以基于文本特性的检测方法为核心,采用多种基于文本特性的检测方法相结合的方式,获得分类检测结果,并最终进行人工确认复核。
4.3目标代码相似性鉴定的实现方案
本案例涉及某侵权案件中的目标代码相似性鉴定,原告方提交的检材为C语言源代码,被告方被保全公证的是目标代码。原告方提交的源代码编译后生成的目标代码与被告方的目标代码存在较大差异。本案例的特点是,涉及二进制代码的比对,反汇编后有3000多个汇编函数,且汇编代码存在较大差异。本案例鉴定实施方案见下图2所示。
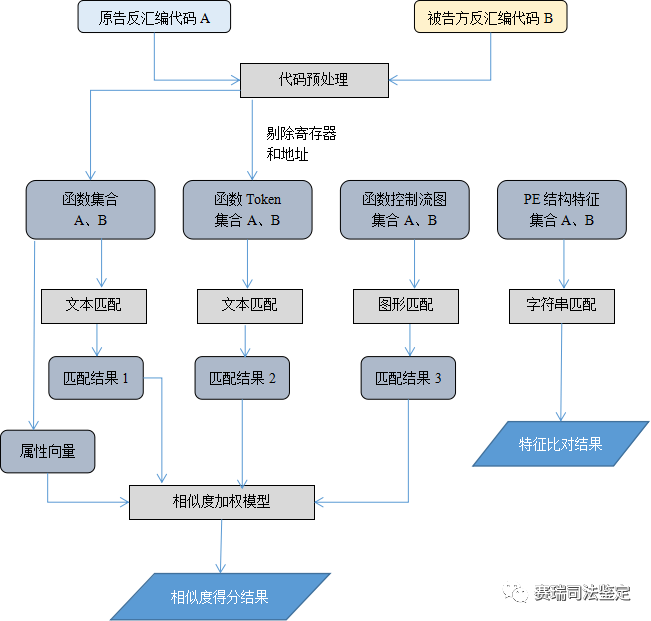
图2 二进制目标代码相似性鉴定方案
在多数软件侵权案件中,初期取证甚至在审判阶段都很难获取到涉侵权方的软件源代码,一般仅能获取目标代码,因此在实践中软件目标代码的比对更为常见。虽然源代码级的复制和修改会体现在相应的二进制代码中,但即使同一源代码经过不同的编译器和优化配置,针对不同的硬件平台,编译得到的二进制代码也不尽相同。即使将二进制代码反编译成汇编语言进行比对,但由于汇编指令和语法的局限性,使得二进制代码的比对相当于源代码的比对更为复杂,因此在鉴定过程中,需要建立一个以为文本检测为基础,并结合基于程序逻辑、程序特征向量等多种技术手段的检测模型。最后,对相似度得分情况进行人工确认复核,并记录特征比对结果。
结语
从上述的案例可以看出,尽管在司法鉴定实施过程中应用代码相似性检测技术减轻了鉴定实施的工作量,并使得检测结果更为高效和客观,但由于鉴定领域的特殊性、复杂性、严谨性,在鉴定比对中,鉴定人仍需对这些工具和方法的使用持谨慎态度,形成以“工具鉴定为辅,人员鉴定为主”的技术应用模式,避免因检测工具或者方法的使用不当造成鉴定结果偏差,以此确保鉴定检测结果的准确性。
作者简介:文静,高级工程师,就职于国家工业信息安全发展研究中心评测鉴定所,主要研究领域为计算机软件领域知识产权鉴定、电子数据鉴定。邮箱:wenjing@infoip.org 联系电话:15110086002
声明:本文来自赛瑞司法鉴定,版权归作者所有。文章内容仅代表作者独立观点,不代表士冗科技立场,转载目的在于传递更多信息。如有侵权,请联系 service@expshell.com。
 联系我们
联系我们 在线留言
在线留言 京公网安备11011202100645号
京公网安备11011202100645号