
在数据隐私保护领域,联邦学习被认为是一种高效且安全的解决方案。但联邦学习真的无懈可击吗?在英伟达最近的一项研究中,研究者通过反转批平均梯度完全恢复了隐藏的原始图像,引发了人们对联邦学习安全性的重新思考。
联邦学习因为数据不出本地的隐私保护策略,一直被人们认为是高效解决 AI 计算问题,并保护个人数据的重要方向,目前已经出现了大量相关的研究和应用。然而,随着目前法律法规对于数据限制的加深,从梯度、模型参数中反推出用户数据的方法正在显现。
在不少情况下,利用被模糊的数据,以及机器学习处理过程中的参数,我们能够重建出一个人的基本信息。而最近,英伟达的研究人员更进一步,甚至直接通过机器学习中的梯度数据重建了图像。新的研究让人们不禁怀疑:联邦学习难道实际上并不安全?
具体地,研究者提出了一种 GradInversion 方法,通过反转给定的批平均梯度(batch-averaged gradients)从随机噪声中恢复隐藏的原始图像。该研究已被计算机视觉顶会 CVPR 2021 接收。

论文链接:https://arxiv.org/pdf/2104.07586.pdf
研究者提出了一种标签修复方法,利用最后的全连接层梯度来恢复真值标签。他们还提出了一种群体一致性正则化项,它是基于多种子优化和图像配准,用于提升图像重建质量。实验表明,对于 ResNet-50 这样的深度网络,利用批平均梯度完全恢复细节丰富的单个图像是可行的。

研究者在论文中表示,与 BigGAN 等 SOTA 生成对抗网络相比,他们提出的非学习(non-learning)图像恢复方法可以恢复隐藏输入数据的更丰富细节。
更重要的是,即使当图像批大小增加至 48,通过反转批梯度,该方法依然可以完全恢复 224×224 像素大小且具有高保真度和丰富细节的图像。
对于这项研究的结果,有网友认为:「这就是差分隐私(differential privacy, DP)存在的理由,没有差分隐私的联邦学习无法保证隐私。」

研究概述
下图 1(a)中,研究者提出 GradInversion,通过反转批平均梯度来恢复高保真度和丰富细节的隐藏训练图像;图 1(b)展示了将噪声变换至输入图像的优化过程,首先从全连接层的梯度中恢复标签,然后在保真度正则化和基于注册的群体一致性正则化条件下优化输入以匹配目标梯度,从而提升重建质量。
这种方法能够从 ResNet-50 批梯度中恢复 224×224 像素的 ImageNet 图像样本,这在以前是无法实现的。
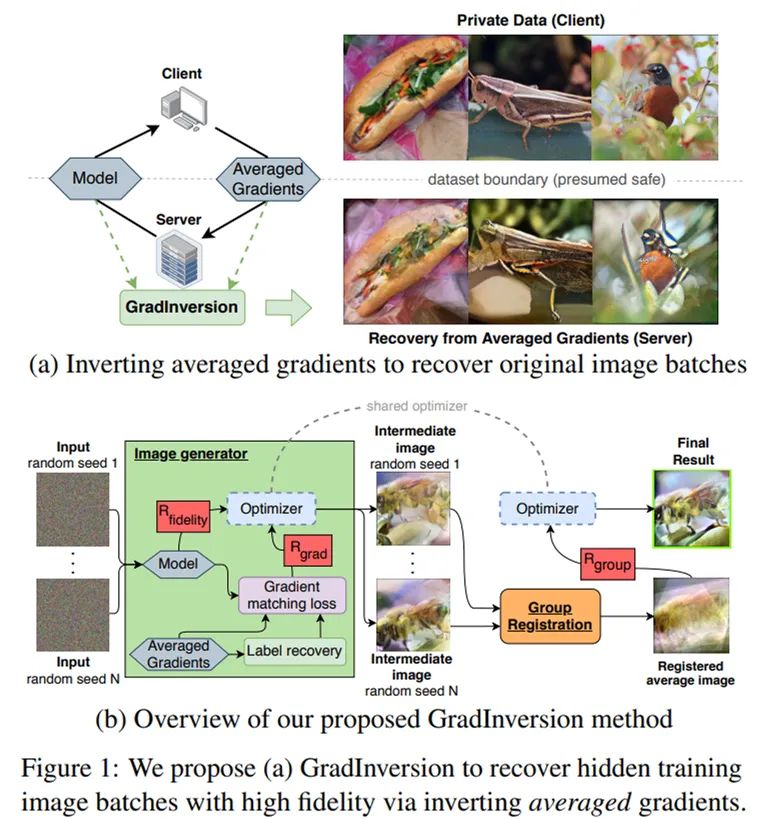
方法概览。
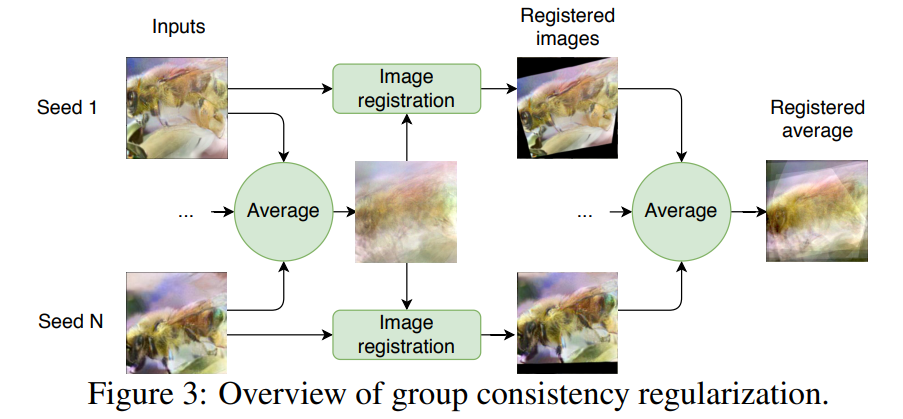
由于卷积神经网络(CNN)的平移不变性,基于梯度的反转面临另一项挑战——目标对象的精确定位。在理想场景中,优化可以收敛至一个真值(ground truth)。
但如下图 2 所示,研究者观察到,当使用不同的 seed 重复优化过程时,每个优化过程均可以得到局部最小值。这些局部最小值在所有层级上分配语义正确的图像特征,但彼此之间又有不同:图像围绕着真值变换,并专注不同的细节。

研究者提出了一种群体一致性正则化项,它通过联合优化的方式同时利用多个 seed,具体流程如下图 3 所示:
实验结果
研究者以 224×224 像素为范例,在大规模 1000-class ImageNet ILSVRC 2012 数据集上对该方法在分类任务上的效果进行了评估。
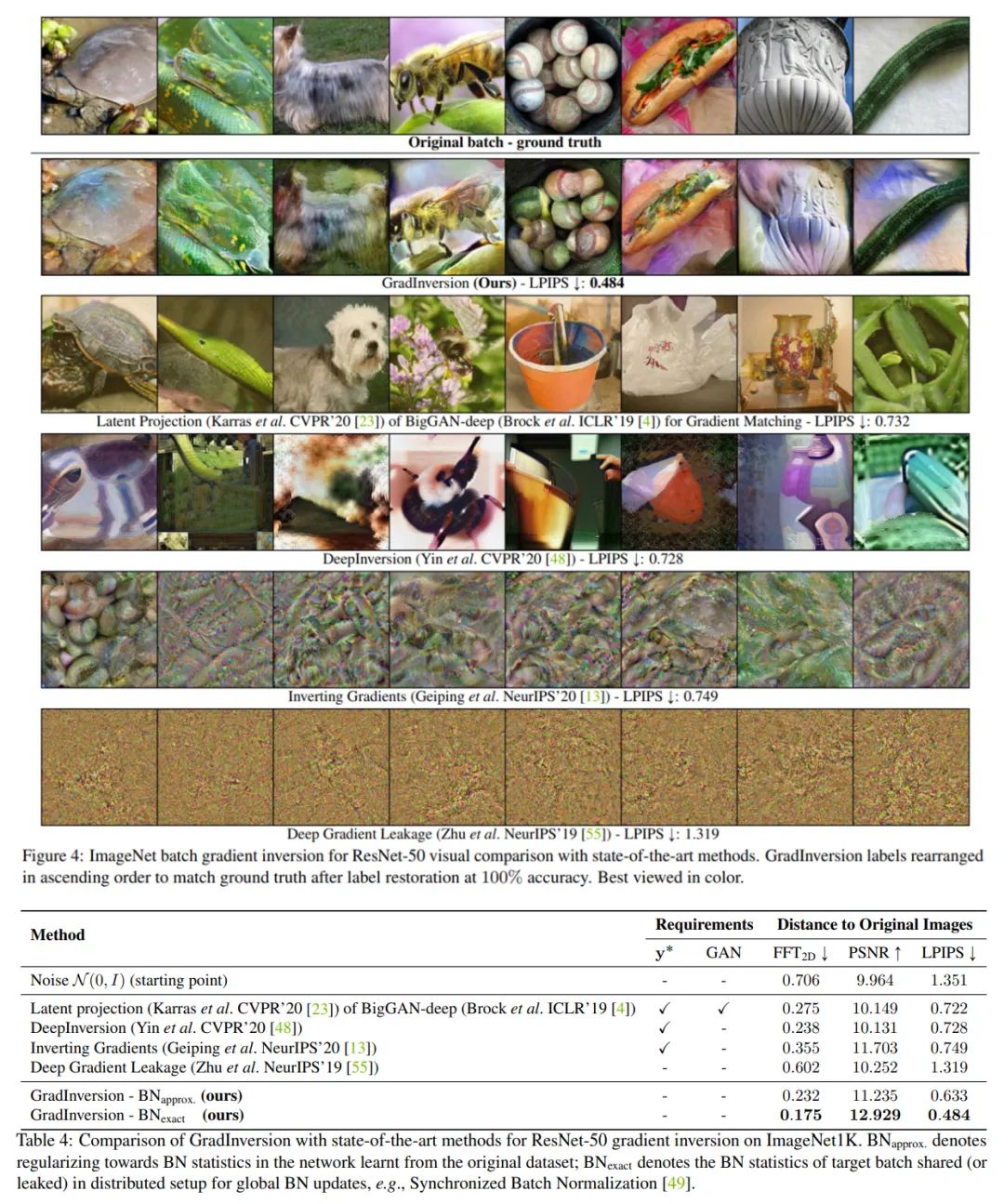
首先,他们在批大小为 8 时,对 224×224 像素大小的图像进行了效果对比。下图 4 和表 4 分别为 GradInversion 方法与 Latent Projection、DeepInversion、Inverting Gradients 和 Deep Gradient Leakage 等 SOTA 方法的定性和定量对比,结果显示该方法在视觉效果和数值上均胜出。
接着,研究者增加了批大小,使用 32GB 英伟达 V100 GPU 将批大小增至 48。如下图 6 所示,随着批大小的增加,可恢复图像的数量逐渐减少。

不过,GradInversion 方法依然可以获取一定数量的原始视觉信息,有时还能实现完整的重建,具体如下图 7 所示:
一作简介
该论文的一作是尹洪旭(Hongxu Yin),2015 年毕业于新加坡南洋理工大学电气与电子工程专业,获工学学士学位,在美国普林斯顿大学电气工程系攻读博士学位,现在是英伟达(硅谷)研究科学家。
他的研究集中在高效的深度神经网络、无数据模型压缩 / 神经结构搜索和边缘医疗推理。
个人主页:https://scholar.princeton.edu/hongxu
声明:本文来自机器之心,版权归作者所有。文章内容仅代表作者独立观点,不代表士冗科技立场,转载目的在于传递更多信息。如有侵权,请联系 service@expshell.com。
 联系我们
联系我们 在线留言
在线留言 京公网安备11011202100645号
京公网安备11011202100645号